* 本文的部分示意图使用了 AI 辅助创作,其余有明确标注的示意图则引用自参考文献。
若无特别说明,本文中的单个向量默认视为列向量。比如,在 RNN、BPTT 与 Bahdanau Attention 部分,$\boldsymbol{x}_t,\boldsymbol{h}_t,\boldsymbol{s}_t,\boldsymbol{a}_t$ 等单个向量都按列向量书写。
而在 attention 与 Transformer 章节的矩阵记号中,为便于书写整段序列的矩阵乘法,序列矩阵统一按行堆叠:若第 $i$ 个 token 的表示向量为列向量 $\boldsymbol{x}_i$,则矩阵 $\boldsymbol{X}$ 的第 $i$ 行为 $\boldsymbol{x}_i^T$。相应地,$\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}$ 的第 $i$ 行分别记为 $\boldsymbol{q}_i^T,\boldsymbol{k}_i^T,\boldsymbol{v}_i^T$。
Token 指模型处理数据的最小单位。在 CV(Computer Vision,计算机视觉)中常指图像切分后的 patch,在音频中指离散化的特征片段,而在 NLP(Natural Language Processing,自然语言处理)中则是指文本分词(字、词或子词)。本文后续所指的 token 均可以被理解为 NLP 范畴下的文本单元,token embedding 则是通过嵌入层将 token ID 映射至连续向量空间中的稠密语义表示。
RNN
背景引入
在前文 MLP 与 BP 算法的数学原理 中,我们从数学上推导了普通 FFN(Feed-Forward Network,前馈神经网络)的误差反向传播算法,并最终编码实现了一个能够训练并完成分类任务的 MLP。
MLP(Multi-Layer Perceptron,多层感知机)是最经典、最基础的一种前馈神经网络,它只接受固定维度的张量 $\boldsymbol{x}$,并在经过内部若干层全连接层的非线性变换 $f(\boldsymbol{x})=\varphi(\boldsymbol{Wx}+\boldsymbol{b})$ 后,最终输出固定维度的张量 $\boldsymbol{y}$。对于能够确定输入与输出张量维度的任务,例如图像识别、缺陷检测等,输入输出张量维度固定是能够接受的。但是,对于序列数据,特别是那些具有强时间相关性的序列数据,譬如股票指数的时间序列、自然语言等,MLP 便显得力不从心了,主要体现在:
- 输入维度固定,意味着无法处理可变长序列;
- 固定维度与无记忆性的假设,使得模型更难捕捉到序列元素间的依赖关系。
一个简单的改进就是 RNN(Recurrent Neural Network,循环神经网络)。RNN 是一种基本的序列模型,下面介绍 RNN,并做简要的数学推导。
参考文献:
- Y. Bengio, P. Simard and P. Frasconi, “Learning long-term dependencies with gradient descent is difficult,” in IEEE Transactions on Neural Networks, vol. 5, no. 2, pp. 157-166, March 1994, doi: 10.1109/72.279181.
基本结构
RNN 的核心公式是如下的递归表达式,
$$ \boldsymbol{h}_t=\varphi(\boldsymbol{W}_h\boldsymbol{h}_{t-1}+\boldsymbol{W}_x\boldsymbol{x}_{t}+\boldsymbol{b}) \tag{1} $$其中 $t$ 是时间步(Timestep)、$\boldsymbol{h}$ 为隐状态(Hidden State),$\boldsymbol{W}_h$ 与 $\boldsymbol{W}_x$ 是两个能够被训练与优化的权重参数张量,$\boldsymbol{b}$ 是能够被训练与优化的偏置(Bias),$\varphi$ 是一个保持向量维度的激活函数(Activation Function)。
如果没有偏置项,$\boldsymbol{W}_h\boldsymbol{h}_{t-1}+\boldsymbol{W}_x\boldsymbol{x}_{t}$ 只能够做到线性变换,而不能做到仿射变换。

我们认为,$\boldsymbol{h}_t$ 包含了 $\{\boldsymbol{x}_i\}^{t}_{i=1}$ 的信息,因为 $(1)$ 式本质上是一个递推公式,在完全展开后可见 $\boldsymbol{h}_t$ 由变量 $\{\boldsymbol{h}_i\}^{t-1}_{i=1}$ 与 $\{\boldsymbol{x}_i\}^{t}_{i=1}$ 唯一决定。RNN 通过显式地对时间步与历史状态进行建模,能够累积长期信息,这是 RNN 善于处理序列问题的一个重要因素。
这里要注意的关键点是 $\boldsymbol{W}_h$、$\boldsymbol{W}_x$ 和 $\boldsymbol{b}$ 同时间步完全无关,即对于任何时间步,权重参数都是全局共享的,这是 RNN 擅长 NLP 之类的长建模序列依赖的另一个重要因素。
从权重规模看,RNN 的权重规模是固定的,不随输入序列长度 $T$ 而变化;而如果强行用 MLP 处理序列,常见的做法是要么让每个时间步输入 $\boldsymbol{x}_t$ 共享同一份权重参数,要么将所有时间步输入 $\{\boldsymbol{x}_i\}^{T}_{i=1}$ 拼接后再将其整体作为 MLP 的输入。然而,前者丢失了时间依赖性信息(所以 RNN 在其基础上设计了隐状态 $\boldsymbol{h}_t$),后者则使得权重规模随序列长度 $T$ 线性增长,显然这都不能称为很好的做法。
若输入维度为 $d_x$、隐状态维度为 $d_h$、序列长度为 $T$,则 RNN 在单个时间步的前向计算复杂度大致为 $O(d_h^2+d_xd_h)$,整段序列的前向计算复杂度则为 $O\big(T(d_h^2+d_xd_h)\big)$。这说明 RNN 的参数规模虽然不随 $T$ 增长,但计算量仍会随序列长度线性增长,并且无法在时间维度上完全并行化。
不严谨地,我们可以把 RNN 视为在时间维度上权重共享且具有隐状态的一种 MLP 改进。换言之,RNN 是在时间维度上对同一个 MLP 进行递归展开的结构。
RNN 的最终输出是可以灵活选取的,不存在统一的「硬规定」。可以只使用最后一个隐状态 $\boldsymbol{h}_T$ 或对其做进一步的变换 $g(\boldsymbol{h}_T)$,常见场景有情感分析、垃圾邮件识别与时间序列预测任务;也可以使用隐状态序列 $\{\boldsymbol{h}_i\}$,常见场景有序列标注(譬如词性标注)、语音识别与早期机器翻译的 Decoder。
但通常而言,RNN 是无法直接做到将可变长序列作为输出的,因此后来提出了基于 RNN 的 Encoder–Decoder,该架构实现使神经网络真正地做到序列至序列的映射。
计算 $\boldsymbol{h}_1$ 时,需要我们特别提供 $\boldsymbol{h}_0$,最常见的做法是取 $\boldsymbol{h}_0$ 为零值。也可以将 $\boldsymbol{h}_0$ 设计为一个可学习的参数,这样可以为 RNN 提供一个默认的初始上下文信息。
BPTT 算法
在前文中我们推导了 MLP 的 BP 算法(Backpropagation Algorithm,反向传播算法)中梯度的形式。RNN 考虑了时间维度,我们称适用这类模型的最优化算法为 BPTT 算法(Backpropagation Through Time Algorithm,沿时间的反向传播算法)。下面我们推导 RNN 的 BPTT 算法中梯度的形式。
这里花了很大的篇幅推导 BPTT 中梯度的形式,这是有必要的,因为知晓了梯度后我们就可以很容易地使用梯度下降法等最优化算法训练模型了。
为方便表示,记
$$ \boldsymbol{a}_t\triangleq\boldsymbol{W}_h\boldsymbol{h}_{t-1}+\boldsymbol{W}_x\boldsymbol{x}_t+\boldsymbol{b} \tag{2} $$则根据 $(1)$ 式,隐状态 $\boldsymbol{h}_t$ 可被表示为
$$ \boldsymbol{h}_t=\varphi(\boldsymbol{a}_t) \tag{3} $$通常假设 $\mathcal{L}_t$ 仅依赖 $\boldsymbol{h}_t$,在假设成立的前提下总损失为
$$ \mathcal{L}=\sum_{t=1}^{T}\mathcal{L}_t \tag{4} $$其中第 $t$ 时间步的损失 $\mathcal{L}_t$ 不直接依赖于 $\boldsymbol{W}_h,\boldsymbol{W}_x,\boldsymbol{b}$,而是由一系列隐状态 $\{\boldsymbol{h}_i\}^t_{i=1}$ 传递的。因此,要计算 $\mathcal{L}$ 对 $\boldsymbol{W}_h,\boldsymbol{W}_x,\boldsymbol{b}$ 的梯度,我们首先需要讨论 $\mathcal{L}$ 对 $\boldsymbol{a}_t$ 与 $\boldsymbol{h}_t$ 的梯度。按列向量约定,我们记
$$ \boldsymbol{\delta}_t\triangleq\frac{\partial\mathcal{L}}{\partial\boldsymbol{a}_t},\quad \bar{\boldsymbol{h}}_t\triangleq\frac{\partial\mathcal{L}}{\partial\boldsymbol{h}_t} \tag{5} $$接下来我们先推导出 $\bar{\boldsymbol{h}}_t$ 与 $\boldsymbol{\delta}_t$ 的形式——这是 BPTT 数学推导中最重要的一环。
这里要明确根据式子 $\boldsymbol{h}_t=\varphi(\boldsymbol{a}_t)$ 可知,总损失 $\mathcal{L}$ 对 $\boldsymbol{a}_t$ 的直接依赖路径是唯一的,即通过第 $t$ 时间步的隐状态 $\boldsymbol{h}_t$;而 $\boldsymbol{h}_t$ 又通过两种路径影响 $\mathcal{L}$:
直接影响路径:$\boldsymbol{h}_t$ 直接影响当前时刻的损失 $\mathcal{L}_t$,进而影响总损失 $\mathcal{L}$;
间接影响路径(通过递归关系):$\boldsymbol{h}_t$ 作为下一时刻的输入,间接影响后续时刻的所有损失 $\mathcal{L}_{t+1},\mathcal{L}_{t+2},\cdots,\mathcal{L}_{T}$,进而影响总损失 $\mathcal{L}$。这类影响路径是 RNN 所特有的,是时间依赖的体现。
然而,我们不能直接计算出 $\forall i>t,\frac{\partial\mathcal{L}_i}{\partial\boldsymbol{h}_t}$,因为若将所有 $\forall i>t,\mathcal{L}_i$ 直接展开到 $\boldsymbol{h}_t$,我们将得到一个指数爆炸的间接路径数量;故我们应考虑藉由递归式 $\boldsymbol{a}_{t+1}=\boldsymbol{W}_h\boldsymbol{h}_{t}+\boldsymbol{W}_x\boldsymbol{x}_{t+1}+\boldsymbol{b}$,通过中间变量 $\boldsymbol{a}_{t+1}$ 表示 $\boldsymbol{h}_t$ 对总损失 $\mathcal{L}$ 造成的所有间接影响。
因此,我们根据链式法则,先有
$$ \begin{aligned} \bar{\boldsymbol{h}}_t &=\frac{\partial\mathcal{L}}{\partial\boldsymbol{h}_t}\\ &=\frac{\partial\mathcal{L}_t}{\partial\boldsymbol{h}_t} +\left(\frac{\partial\boldsymbol{a}_{t+1}}{\partial\boldsymbol{h}_t}\right)^T \frac{\partial\mathcal{L}}{\partial\boldsymbol{a}_{t+1}}\\ &=\frac{\partial\mathcal{L}_t}{\partial\boldsymbol{h}_t} +\boldsymbol{W}_h^T\boldsymbol{\delta}_{t+1} \end{aligned} \tag{6} $$进一步,
$$ \begin{aligned} \boldsymbol{\delta}_t &=\frac{\partial\mathcal{L}}{\partial\boldsymbol{a}_t}\\ &=\left(\frac{\partial\boldsymbol{h}_t}{\partial\boldsymbol{a}_t}\right)^T\bar{\boldsymbol{h}}_t\\ &=\mathrm{diag}\big(\varphi'(\boldsymbol{a}_t)\big)\bar{\boldsymbol{h}}_t\\ &=\Bigg(\frac{\partial\mathcal{L}_t}{\partial\boldsymbol{h}_t}+\boldsymbol{W}^{T}_{h}\boldsymbol{\delta}_{t+1}\Bigg)\odot\varphi'(\boldsymbol{a}_t) \end{aligned} \tag{7} $$这里先把梯度回传到 $\boldsymbol{h}_t$,再由 $\boldsymbol{h}_t=\varphi(\boldsymbol{a}_t)$ 回传到 $\boldsymbol{a}_t$,这样各项的行/列维度始终一致。
计算出 $\boldsymbol{\delta}_t$ 后,我们就可以方便地表示出总损失 $\mathcal{L}$ 对 $\boldsymbol{W}_h,\boldsymbol{W}_x,\boldsymbol{b}$ 的梯度了。
$$ \boxed{\frac{\partial\mathcal{L}}{\partial\boldsymbol{W}_h}=\sum^T_{t=1}\frac{\partial\mathcal{L}}{\partial\boldsymbol{a}_t}\frac{\partial\boldsymbol{a}_t}{\partial\boldsymbol{W}_h}=\sum^T_{t=1}\boldsymbol{\delta}_t\frac{\partial(\boldsymbol{W}_h\boldsymbol{h}_{t-1}+\boldsymbol{W}_x\boldsymbol{x}_t+\boldsymbol{b})}{\partial\boldsymbol{W}_h}=\sum^T_{t=1}\boldsymbol{\delta}_t\boldsymbol{h}^T_{t-1}} \tag{8} $$$$ \boxed{\frac{\partial\mathcal{L}}{\partial\boldsymbol{W}_x}=\sum^T_{t=1}\frac{\partial\mathcal{L}}{\partial\boldsymbol{a}_t}\frac{\partial\boldsymbol{a}_t}{\partial\boldsymbol{W}_x}=\sum^T_{t=1}\boldsymbol{\delta}_t\frac{\partial(\boldsymbol{W}_h\boldsymbol{h}_{t-1}+\boldsymbol{W}_x\boldsymbol{x}_t+\boldsymbol{b})}{\partial\boldsymbol{W}_x}=\sum^T_{t=1}\boldsymbol{\delta}_t\boldsymbol{x}^T_{t}} \tag{9} $$$$ \boxed{\frac{\partial\mathcal{L}}{\partial\boldsymbol{b}}=\sum^T_{t=1}\frac{\partial\mathcal{L}}{\partial\boldsymbol{a}_t}\frac{\partial\boldsymbol{a}_t}{\partial\boldsymbol{b}}=\sum^T_{t=1}\boldsymbol{\delta}_t\frac{\partial(\boldsymbol{W}_h\boldsymbol{h}_{t-1}+\boldsymbol{W}_x\boldsymbol{x}_t+\boldsymbol{b})}{\partial\boldsymbol{b}}=\sum^T_{t=1}\boldsymbol{\delta}_t} \tag{10} $$我们再分别导出回归任务场景均方误差与分类任务场景交叉熵损失下局部误差项的具体表达式,记真实值为 $\boldsymbol{y}'_t$,并记
$$ \boldsymbol{g}_t=\frac{\partial\mathcal{L}_t}{\partial\boldsymbol{h}_t},\quad\boldsymbol{a}_t=\boldsymbol{W}_h\boldsymbol{h}_{t-1}+\boldsymbol{W}_x\boldsymbol{x}_t+\boldsymbol{b} \tag{11} $$对于均方误差损失函数 $\mathcal{L}_{\text{MSE}}=\frac{1}{2}\Vert\boldsymbol{y}_t-\boldsymbol{y}'_t\Vert^2$,若第 $t$ 时间步的输出由隐状态 $\boldsymbol{h}_t$ 经线性层得到,即
$$ \boldsymbol{y}_t=\boldsymbol{W}_y\boldsymbol{h}_t+\boldsymbol{b}_y \tag{12} $$则
$$ \boldsymbol{g}_t=\bigg(\frac{\partial\boldsymbol{y}_t}{\partial\boldsymbol{h}_t}\bigg)^T\frac{\partial\mathcal{L}_{\text{MSE}}}{\partial\boldsymbol{y}_t}=\boldsymbol{W}^T_y(\boldsymbol{y}_t-\boldsymbol{y}'_t) \tag{13} $$对于交叉熵损失函数 $\mathcal{L}_{\text{CE}}=-\sum\limits^K_{i=1}y'_{t,i}\log y_{t,i}$,考虑真实标签为 one-hot 编码,若第 $t$ 时间步的输出由隐状态 $\boldsymbol{h}_t$ 经线性层得到 logits $\boldsymbol{l}_t$ 并将 logits 作为 Softmax 函数输入最终输出概率分布 $\boldsymbol{y}_t$,即
$$ \boldsymbol{l}_t=\boldsymbol{W}_y\boldsymbol{h}_t+\boldsymbol{b}_y \tag{14} $$$$ \boldsymbol{y}_t=\mathrm{Softmax}(\boldsymbol{l}_t) \tag{15} $$由 Softmax 与交叉熵复合函数的导数性质,不难知道
$$ \frac{\partial\mathcal{L}_{\text{CE}}}{\partial\boldsymbol{l}_t}=\boldsymbol{y}_t-\boldsymbol{y}'_t \tag{16} $$因此有
$$ \boldsymbol{g}_t=\bigg(\frac{\partial\boldsymbol{l}_t}{\partial\boldsymbol{h}_t}\bigg)^T\frac{\partial\mathcal{L}_{\text{CE}}}{\partial\boldsymbol{l}_t}=\boldsymbol{W}^T_y(\boldsymbol{y}_t-\boldsymbol{y}'_t) \tag{17} $$于是结合 $(6)$ 式,完整的 $\boldsymbol{\delta}_t$ 仍满足
$$ \boldsymbol{\delta}_t=\Big(\boldsymbol{g}_t+\boldsymbol{W}^{T}_{h}\boldsymbol{\delta}_{t+1}\Big)\odot\varphi'(\boldsymbol{a}_t) \tag{18} $$可以看到,在上述前提下,BPTT 针对回归任务与分类任务的梯度计算在形式上是十分相似的,仅在误差项的来源上有所差异。
交叉熵损失(Cross-Entropy Loss)是多分类任务中最常见的损失函数,用于衡量模型预测概率分布与真实标签分布之间的差异。从信息论的角度看,交叉熵 $H(P,Q)=-\sum\limits_{x}P(x)\log Q(x)$ 意味着当真实分布为 $P$ 时基于预测分布 $Q$ 编码所需的平均信息量。对于 one-hot 标签分类任务,由于真实分布 $P$ 退化为 one-hot 分布,交叉熵损失最终会退化为 $-\log Q(y_{\text{true}})$,即最大化真实类别的预测概率。
KL 散度(Kullback-Leibler Divergence)$D_{\text{KL}}(P||Q)=H(P,Q)-H(P)$ 表示使用预测分布 $Q$ 所需要付出的额外成本, 其中 $H(P)$ 为真实分布 $P$ 的香农熵 $-\sum\limits_{x}P(x)\log P(x)$,代表最优编码信息量。因此,在监督学习下最小化交叉熵等价于最小化 KL 散度,即最小化额外编码成本。
局限
RNN 的循环结构使得模型具备了跨时间维度共享状态的能力。我们可以列举出 RNN 的若干优点:
- 能够轻松地处理可变长序列输入;
- 参数量与序列长度无关;
- 具备一定程度的「记忆」能力,因为任何时刻的隐状态在理论上都蕴含了过去时间步的历史信息;
- ……
虽然 RNN 的参数量不随序列长度改变,但从其原理不难看到前向计算量与训练开销仍会随序列长度线性增长。
RNN 的设计的确十分优雅,然而从上述推导中,我们能够发现 RNN 依然存在着若干缺陷:
- 没有解决长期依赖(Long-term Dependency)的问题,因为 RNN 内部存在梯度爆炸 / 梯度消失的现象,这使得早期信息难以长期保留;
- 无法直接访问全部的历史信息:当前时间步 $t$ 只利用了上一时间步输出的隐状态 $\boldsymbol{h}_{t-1}$,尽管 $\boldsymbol{h}_{t-1}$ 理论上蕴含了过去的历史信息,但终归是将所有历史信息全部压缩编码到 $\boldsymbol{h}_{t-1}$ 这一个量中了,而无法直接利用过去完整的历史信息 $\{\boldsymbol{h}_i\}^{t-1}_{i=1}$。注意力(Attention)机制解决了这个问题,使得模型在任意时间步都能够完整访问并利用过去某一时间步的信息;
- 串行计算:在计算隐状态时,RNN 只能按时间步顺序串行化计算,因为 $\forall t,\boldsymbol{h}_{t}$ 依赖于 $\boldsymbol{h}_{t-1}$。Transformer 彻底解决了这个问题,实现了隐状态的并行计算(但推理时输出 token 仍按时间步顺序进行)。
这里从数学上简要说明 RNN 为什么存在梯度爆炸 / 梯度消失的风险。我们讨论早期隐状态 $\boldsymbol{h}_k$ 对总损失 $\mathcal{L}$ 的影响程度,这在数值上等价于关注 $\frac{\partial\mathcal{L}}{\partial\boldsymbol{h}_k}$。在列向量约定下,根据链式法则有
$$ \begin{aligned} \frac{\partial\mathcal{L}}{\partial\boldsymbol{h}_k}&=\sum^T_{t=k}\frac{\partial\mathcal{L}_t}{\partial\boldsymbol{h}_k}\\ &=\sum^T_{t=k}\left(\frac{\partial\boldsymbol{h}_t}{\partial\boldsymbol{h}_k}\right)^T\frac{\partial\mathcal{L}_t}{\partial\boldsymbol{h}_t}\\ &=\sum^T_{t=k}\left(\prod^t_{i=k+1}\frac{\partial\boldsymbol{h}_i}{\partial\boldsymbol{h}_{i-1}}\right)^T\frac{\partial\mathcal{L}_t}{\partial\boldsymbol{h}_t}\\ &=\sum^T_{t=k}\left(\prod^t_{i=k+1}\mathrm{diag}\big(\varphi'(\boldsymbol{a}_i)\big)\boldsymbol{W}_h\right)^T\frac{\partial\mathcal{L}_t}{\partial\boldsymbol{h}_t}\\ &=\sum^T_{t=k}\Big(\boldsymbol{W}_h^T\mathrm{diag}\big(\varphi'(\boldsymbol{a}_t)\big)\cdots\boldsymbol{W}_h^T\mathrm{diag}\big(\varphi'(\boldsymbol{a}_{k+1})\big)\Big)\frac{\partial\mathcal{L}_t}{\partial\boldsymbol{h}_t} \end{aligned} \tag{19} $$其中当 $t=k$ 时,上式中的空乘积按单位矩阵理解。因此,$\frac{\partial\mathcal{L}}{\partial\boldsymbol{h}_k}$ 可以被分解为若干矩阵连乘的和,并且跨越的时间步愈长,连乘的矩阵愈多。
Hochreiter 与 Schmidhuber 在 1997 年指出,保持时间依赖性的必要条件是长期保持梯度。然而,
$$ \big\Vert\boldsymbol{W}_h^T\mathrm{diag}\big(\varphi'(\boldsymbol{a}_i)\big)\big\Vert\leqslant\Vert\boldsymbol{W}_h\Vert\big\Vert\mathrm{diag}\big(\varphi'(\boldsymbol{a}_i)\big)\big\Vert \tag{20} $$由于激活函数的导数往往是有界的(导数无界的激活函数易导致更严重的梯度爆炸 / 梯度消失,极少考虑),因此可认为 $\big\Vert\mathrm{diag}\big(\varphi'(\boldsymbol{a}_i)\big)\big\Vert\leqslant\gamma<\infty$。实际上,对于常见的激活函数(Sigmoid、Tanh、ReLU 等),通常有 $\gamma\leqslant 1$。在 $\gamma\leqslant 1$ 的假设下,有
$$ \bigg\Vert\frac{\partial\mathcal{L}}{\partial\boldsymbol{h}_k}\bigg\Vert=\Bigg\Vert\sum^T_{t=k}\Big(\boldsymbol{W}_h^T\mathrm{diag}\big(\varphi'(\boldsymbol{a}_t)\big)\cdots\boldsymbol{W}_h^T\mathrm{diag}\big(\varphi'(\boldsymbol{a}_{k+1})\big)\Big)\frac{\partial\mathcal{L}_t}{\partial\boldsymbol{h}_t}\Bigg\Vert\leqslant\sum^T_{t=k}\Bigg\Vert\frac{\partial\mathcal{L}_t}{\partial\boldsymbol{h}_t}\Bigg\Vert\big(\gamma\Vert\boldsymbol{W}_h\Vert\big)^{t-k} \tag{21} $$不严谨地说,若 $\gamma\Vert\boldsymbol{W}_h\Vert<1$,则 $\lim\limits_{t-k\to\infty}\big(\gamma\Vert\boldsymbol{W}_h\Vert\big)^{t-k}\to0$,梯度 $\frac{\partial\mathcal{L}}{\partial\boldsymbol{h}_k}$ 便呈指数级衰减,这使得早期隐状态 $\boldsymbol{h}_k$ 对总损失的影响变得微乎其微。如需更严谨的证明,请参考 Bengio、Simard 与 Frasconi 在 1994 年的研究。
Hochreiter 与 Schmidhuber 提出 LSTM 的动机,正是为了解决 RNN 的结构性问题所带来的梯度爆炸 / 梯度消失。LSTM 的核心创新点是通过添加精妙的输入门、遗忘门与输出门机制,使得隐状态链路径上的梯度不再是多个矩阵连乘,而只需要连乘多个遗忘门的值——而遗忘门是可学习的,这使得梯度消失的问题得到了很大的缓解。

下面我们跳过 LSTM、GRU 等若干 RNN 的改良,让我们直接关注划时代的注意力机制。
虽然不做展开,但我想指出:即使 LSTM 大大缓解了梯度消失的问题,我依然认为 LSTM 存在着严重的过度设计。尽管 LSTM 通过复杂的机制减轻了 RNN 梯度消失的程度,但这也使得模型难以被进一步改造。
相比之下,我更喜欢 GRU 的设计,简洁而有效。
Mamba 模型则以另一种不同于 attention 机制的「通过状态空间模型与并行扫描」思路解决了——或者更准确讲绕开了 RNN 梯度消失的问题。Mamba 相比 Transformer,有下述两个重要特点:
- Mamba 的时间与空间复杂度随序列长度线性增长,而经典 self-attention 的计算复杂度则与序列长度呈平方关系;
- Mamba 通过有限维状态对历史信息进行压缩建模,因此其历史记忆不具备类似 attention 机制的显式 token 级随机访问能力;而 Transformer 可以通过 attention 与 KV Cache 动态检索历史 token 的 Key / Value 表示。
Mamba 与 attention 相融合可能是未来大模型的一个发展趋势,特别是在超长序列问题的领域,Mamba 以较低的计算成本表现出了强大的性能。由于本文的主线是 attention 与 Transformer,因此这里不对 Mamba 展开讨论。
参考文献:
- S. Hochreiter and J. Schmidhuber, “Long Short-Term Memory,” in Neural Computation, vol. 9, no. 8, pp. 1735-1780, 15 Nov. 1997, doi: 10.1162/neco.1997.9.8.1735.
Attention
经典 Encoder–Decoder 的瓶颈
Transformer 最早是被应用在机器翻译领域的,我们可以列出在机器翻译领域神经网络模型发展史的一些关键时间点:
- 1982 ~ 1990:早期 RNN
- 1997:首次提出 LSTM
- 2014:基于 RNN 的 Seq2Seq 模型(经典 Encoder-Decoder)与注意力机制分别被首次提出,随后注意力机制被应用在了 Seq2Seq 上
- 2017:Google Brain 团队在《Attention Is All You Need》中首次提出 Transformer,彻底抛弃 RNN
GPT 的全称是 Generative Pre-trained Transformer,可见 GPT 就是典型的基于 Transformer 的 LLM。而 AI 热潮的起点,我们能很明显地感受到是在 2022 年 11 月前后 GPT-3.5 的突然爆红。其实,在 2017 年首次提出 Transformer 后,次年 GPT-1 就发布了。
这里我们简要介绍基于 RNN 的经典 Encoder–Decoder 架构。Transformer 可认为是在经典 Encoder–Decoder 上彻底抛弃 RNN、全面拥抱 attention 的改进款,因此尽管经典 Encoder–Decoder 放在今天看早已过时,但了解经典 Encoder–Decoder 对我们稍后研究 Transformer 依然是大有裨益的。
Seq2Seq(Sequence to Sequence)是最具代表性的经典 Encoder–Decoder 模型,其出现标志着我们首次拥有了能够将序列映射至序列的神经网络模型。我们以 Seq2Seq 为例,借以阐述 Encoder–Decoder 的主体结构。
通过上文我们可以知道,RNN 擅长将可变长序列作为输入,却不能容易地直接输出可变长序列。在时间序列预测或情感分析的场景下这是没有问题的,但在机器翻译领域却不可接受——毕竟,我们也不希望输入一长串句子,最终只得到固定数量 token 的翻译。为了解决这个问题,2014 年 Seq2Seq 应运而生。在这以前,在机器翻译领域占统治性地位的是 SMT 技术(Statistical Machine Translation,统计机器翻译)。

Seq2Seq 最核心的组成部分是 Encoder 与 Decoder,以一种简单的 Seq2Seq 实现为例,在推理(Inference)阶段:
- Encoder 是一个普通的 RNN,负责将序列映射到一个语义向量(Context Vector)中,记为 $\boldsymbol{c}$。在 encoder 中有隐状态 $\boldsymbol{h}_{t}=\mathrm{RNN}(\boldsymbol{h}_{t-1},\boldsymbol{x}_{t})$,其中 $\boldsymbol{x}_{t}$ 是输入 token 经 embedding 后得到的向量。语义向量 $\boldsymbol{c}$ 取自 RNN 的最后一个隐状态 $\boldsymbol{h}_T$,而 RNN 的结构则决定了 $\boldsymbol{c}$ 是一个固定维度的向量。我们认为,该向量压缩编码了原输入的语义信息。
- Decoder 则是一个自回归(Autoregressive)的 RNN,在输出时通过额外的线性层与 Softmax 函数归一化得到预测 token 的概率分布。为与 encoder 的记号相区分,记 decoder 在第 $t$ 时间步的隐状态为 $\boldsymbol{s}_{t}$。Decoder 的工作流程:
- 将语义向量 $\boldsymbol{c}$ 作为初始隐状态 $\boldsymbol{s}_0$,将特殊的起始标志 token $\langle SOS\rangle$ 作为首个 token,此为初始化状态;
- 在 RNN 的第 $t$ 时间步,将 $t-1$ 输出的 token 进行 embedding 得到向量 $\boldsymbol{e}_{t-1}$,然后令 $\boldsymbol{e}_{t-1}$ 作为第 $t$ 时间步的输入,结合第 $t-1$ 时间步 decoder 的隐状态 $\boldsymbol{s}_{t-1}$,得到输出 $\boldsymbol{s}_{t}=\mathrm{RNN}(\boldsymbol{s}_{t-1},\boldsymbol{e}_{t-1})$;
- 计算输出概率 $\mathrm{Softmax}(\boldsymbol{Ws}_{t}+\boldsymbol{b})$,采样(比如 Top-K、argmax)得到输出 token;
- 重复上述过程,直到输出终止标志 token $\langle EOS\rangle$。
Seq2Seq 还有其他几种常见实现,改动点集中在 decoder 上,主要差异在于 RNN 的内部工作方式。例如,有的实现中会让语义向量 $\boldsymbol{c}$ 替代 $\boldsymbol{e}_{t-1}$ 作为 decoder 的 RNN 每个时间步的输入向量。
在训练阶段会考虑 Teacher Forcing 技巧,让 Decoder 的神经元在训练阶段不再全盘使用上一步的输出,而是有比例地选取正确的序列作为输入。这是因为早期节点的偏差会不断在 RNN 内不断传递,Teacher Forcing 能够缓解这个问题。
总而言之,Seq2Seq 首次使神经网络真正具备了 $\text{seq}\to\text{seq}$ 能力,是模型的工程与系统设计上的一个重要创新。
然而,Seq2Seq 也有着不少缺点,其中最显著的问题是无论输入序列有多长,信息都会被压缩至一个固定维度的语义向量中,这就像试图用一页纸概况整本书的内容,导致早期 Seq2Seq 的长句翻译质量相较于短句翻译明显下滑,表现出明显的长期依赖问题。跨注意力(Cross-Attention)的诞生就是为了解决这一难题,使 Seq2Seq 不再依赖固定维度的单一语义向量,允许 Decoder 能够使用所有过去的隐状态信息。
除此之外,Seq2Seq 还有一些其他局限,包括:
- 以 RNN 作为基础组件,计算串行,效率低下;
- 仍未解决长期依赖问题;
- Teacher Forcing 导致训练与推断不一致,存在暴露偏差(Exposure Bias);
- ……
为解决 encoder 需要将所有输入信息压缩为一个固定长度的语义向量所造成的信息瓶颈问题,在 cross-attention 被提出后,有研究者将 cross-attention 与 Seq2Seq 相结合,这使得 decoder 在生成每一个目标词时都能够直接访问并利用编码器生成的全部隐状态信息,从而显著提升了对长序列的建模能力与文本翻译的质量。
我们将在下文介绍 Seq2Seq 是如何与 attention 相结合的。直到这一步,我们仍未彻底抛弃 RNN。
参考文献:
- Sutskever, Ilya, Oriol Vinyals and Quoc V. Le. “Sequence to Sequence Learning with Neural Networks.” ArXiv abs/1409.3215 (2014): n. pag.
Seq2Seq + Bahdanau Attention
在早期的 Seq2Seq 模型中,如上文所述,decoder 只使用一个由 encoder 在最后时间步输出的语义向量 $\boldsymbol{c}$,这导致了严重的长期依赖问题。因此,我们现在考虑让 decoder 在每个时间步 $t$ 都根据 encoder 的全部隐状态计算一个语义向量 $\boldsymbol{c}_t$,其公式为
$$ \boldsymbol{c}_t=\sum^{T}_{i=1}\alpha_{t,i}\boldsymbol{h}_i \tag{22} $$注意求和上标是 $T$ 而非 $t$,因此 encoder 需要先完成全部时间步的计算,decoder 才能在各时间步据此得到对应的 $\boldsymbol{c}_t$。
其中 $\alpha_{t,i}$ 是第 $i$ 时间步 encoder 及第 $t$ 时间步 decoder 的注意力权重(Attention Weight)、$\boldsymbol{h}_i$ 为第 $i$ 时间步 encoder 的隐状态,满足
$$ \forall t,\ \ \sum^T_{i=1}\alpha_{t,i}=1;\ \ \ \ \forall i,t,\ \ \alpha_{t,i}\geqslant0 \tag{23} $$这样,通过 $\boldsymbol{c}_t$ 模型就能利用上全部历史信息,而且能够按每个时间步的历史信息对当前时间步的重要程度进行加权,体现了「有选择性」地「关注」更重要的历史信息 / encoder。
我们说这体现了模型能够「有选择性」地「关注」更重要的历史信息 / encoder,是因为本质上 $\boldsymbol{c}_t$ 是 encoder 的历史隐状态的加权和。
最早应用在 Seq2Seq 上的 attention 是 Bahdanau Attention,由 Bahdanau、Cho 与 Bengio 在 2014 年提出。这里仅对 Bahdanau Attention 作简要介绍,在后文再着重分析 attention 的统一形式。
现在有两个问题,一是模型如何计算注意力权重,二是模型如何使用 $\boldsymbol{c}_t$。接下来我们以 Bahdanau Attention 为例分别讨论这两个问题。
首先讨论如何计算注意力权重。记 $e_{t,i}$ 为匹配分数(Score),计算公式为
$$ e_{t,i}=\boldsymbol{\omega}^T\tanh(\boldsymbol{W}_s\boldsymbol{s}_{t-1}+\boldsymbol{W}_h\boldsymbol{h}_i+\boldsymbol{b}_a) \tag{24} $$其中 $\boldsymbol{s}_{t-1}$ 为第 $t-1$ 时间步 decoder 的隐状态,$\boldsymbol{h}_i$ 为第 $i$ 时间步 encoder 的隐状态,$\boldsymbol{\omega},\boldsymbol{W}_s,\boldsymbol{W}_h,\boldsymbol{b}_a$ 均为全局共享的可学习参数。我们认为 $e_{t,i}$ 衡量了当前位置的输入信息(时间步 $i$ / encoder 的隐状态 $\boldsymbol{h}_{i}$)与当前已解码状态(时间步 $t-1$ / decoder 的隐状态 $\boldsymbol{s}_{t-1}$)之间的相关程度。
记 $\boldsymbol{z}=\tanh(\boldsymbol{W}_s\boldsymbol{s}_{t-1}+\boldsymbol{W}_h\boldsymbol{h}_i+\boldsymbol{b}_a)$,则 $\tanh(\boldsymbol{W}_s\boldsymbol{s}_{t-1}+\boldsymbol{W}_h\boldsymbol{h}_i+\boldsymbol{b}_a)$ 可视为以 tanh 作为激活函数的线性层,$\boldsymbol{\omega}^T\boldsymbol{z}$ 则可视为另一个线性层。$\boldsymbol{\omega}$ 的意义是使匹配分数结果为一个标量,方便后续的计算与使用,从线性空间的角度看匹配分数 $e_{t,i}$ 是信息向量 $\boldsymbol{z}$ 在方向 $\boldsymbol{\omega}$ 上的投影,通过学习参数 $\boldsymbol{\omega}$,模型能够学习到「怎样的隐状态结果代表着高匹配度,应重点关注」。
最后,对各匹配分数进行 Softmax 归一化
$$ \boldsymbol{\alpha}_{t}=\mathrm{Softmax}(\boldsymbol{e}_{t}),\ \ \ \ \alpha_{t,i}=\frac{\exp(e_{t,i})}{\sum\limits^T_{j=1}\exp(e_{t,j})} \tag{25} $$即可得到注意力权重。
可见,匹配分数 $e_{t,i}$ 在计算过程中会同时使用到 encoder 与 decoder 的隐状态。换言之,尽管 $\boldsymbol{c}_t$ 是 encoder 的隐状态的线性组合加权,但其加权权重却同时使用了 decoder 的信息。这很好理解,当我们在翻译一个句子时,不仅要考虑输入的源文本,也要考虑已经翻译出的部分结果。
接着讨论如何使用 $\boldsymbol{c}_t$。为与输出 token 的记号相区别,这里改用 $\boldsymbol{e}_t$ 表示第 $t$ 时间步生成 token 经 embedding 后的向量。在经典 Seq2Seq 中,一种简单而常见的做法是在 decoder 隐藏层考虑
$$ \boldsymbol{s}_t=\mathrm{RNN}(\boldsymbol{s}_{t-1},\boldsymbol{e}_{t-1}) \tag{26} $$而在 Bahdanau Attention 的改进中,在隐藏层考虑
$$ \boldsymbol{s}_t=\mathrm{RNN}\big(\boldsymbol{s}_{t-1},[\boldsymbol{e}_{t-1};\boldsymbol{c}_t]\big) \tag{27} $$在输出层考虑
$$ P(y_t)=\mathrm{Softmax}\big(\boldsymbol{W}[\boldsymbol{s}_t;\boldsymbol{c}_t]+\boldsymbol{b}\big) \tag{28} $$其中 $[\boldsymbol{a};\boldsymbol{b}]$ 表示将两个向量按特征维拼接(concat),例如 $\boldsymbol{a}\in\mathbb{R}^p,\boldsymbol{b}\in\mathbb{R}^q$,则 $[\boldsymbol{a};\boldsymbol{b}]\in\mathbb{R}^{p+q}$。
参考文献:
- Bahdanau, Dzmitry, Kyunghyun Cho and Yoshua Bengio. “Neural Machine Translation by Jointly Learning to Align and Translate.” CoRR abs/1409.0473 (2014): n. pag.
Attention 的一般数学形式
现在我们来把 Bahdanau Attention 的狭隘视角推广到更一般、更抽象的 attention 视角。
在更一般的 attention 视角下不存在 RNN 中时间步的概念,取而代之的是 token 序列的位置索引。
RNN 的时间步可以被视为某种 token 的位置索引,只不过计算时必须按 token 顺序(时序)递归进行;就 attention 本身而言,是完全可以同时并行计算任意位置 token 间的相关性的,因为他关注的只是 token 间的关系。因此,Bahdanau Attention 也可以被纳入到该体系下。
因此这里事先约定记号的写法:对于第 $i$ 个 token,我们分别用列向量 $\boldsymbol{q}_i,\boldsymbol{k}_i,\boldsymbol{v}_i$ 表示其 query、key、value。当我们把整段序列写成矩阵时,则将这些列向量的转置按行排列;例如,若把全部 value 向量收集成矩阵 $\boldsymbol{V}$,则 $\boldsymbol{V}$ 的第 $i$ 行为 $\boldsymbol{v}_i^T$。
在 Bahdanau Attention 中,公式 $\boldsymbol{c}_t=\sum\limits^{T}_{i=1}\alpha_{t,i}\boldsymbol{h}_i$ 的本质是对历史信息作加权和。Bahdanau Attention 所选取的被加权向量是 RNN 的隐状态,在更一般 attention 形式中,被加权的向量称为 value,将多个 $\boldsymbol{v}_i^T$ 按行排布为矩阵即为所谓的 value 矩阵,记为 $\boldsymbol{V}$。
在 Bahdanau Attention 中,被归一化的权重系数是 $e_{t,i}=\boldsymbol{\omega}^T\tanh(\boldsymbol{W}_s\boldsymbol{s}_{t-1}+\boldsymbol{W}_h\boldsymbol{h}_i+\boldsymbol{b}_a)$,该系数衡量了当前位置的输入信息($\boldsymbol{h}_i$,encoder 的隐状态)与当前解码状态($\boldsymbol{s}_{t-1}$,decoder 的隐状态)间的相关程度。在更一般的 attention 形式中,「当前解码状态 $i$」意味着查询者,即 query;「当前位置的输入信息 $j$」意味着被查询的内容,即 key。类似地,query 矩阵记为 $\boldsymbol{Q}$,key 矩阵记为 $\boldsymbol{K}$,它们的第 $i,j$ 行分别为对应 token 的 query 与 key 向量的转置,即 $\boldsymbol{q}_i^T,\boldsymbol{k}_j^T$。
回到 Bahdanau Attention 的框架中也不难理解,在 Bahdanau Attention 的设计中,我们希望模型能够根据「当前解码状态,$\boldsymbol{s}_{t-1}$,query」查询「当前位置的输入信息,$\boldsymbol{h}_i$,key」得到权重系数,然后根据权重系数对「(历史编码)信息,$\boldsymbol{h}_j$,value」进行加权求和,从而给予一些对当前解码十分重要的信息更多关注,并在一定程度上看轻对当前解码不重要的信息。
我们希望通过 $\boldsymbol{q}_i,\boldsymbol{k}_j$ 计算以得到一个具体的数值,该数值应能够从数值上体现出第 $i$ 个 token 作为 query 与第 $j$ 个 token 作为 key 时的相关程度,就像 Bahdanau Attention 计算匹配分数那样。我们把该矩阵称为 score 或 attention score,记作 $\boldsymbol{S}$,有
$$ \boldsymbol{S}_{ij}=\mathrm{score}(\boldsymbol{q}_i,\boldsymbol{k}_j) \tag{29} $$$\boldsymbol{S}_{ij}$ 表示第 $i$ 个 token 对第 $j$ 个 token 的 attention score,该得分越高,表示第 $i$ 个 token 在编码自己时更应关注第 $j$ 个 token。不难看出,在 Bahdanau Attention 中,$\boldsymbol{S}_{ij}=\boldsymbol{\omega}^T\tanh(\boldsymbol{W}_s\boldsymbol{s}_{i-1}+\boldsymbol{W}_h\boldsymbol{h}_j+\boldsymbol{b}_a)$。
下面是一些经典的 score 设计:
- Additive Attention (Bahdanau Attention):$\boldsymbol{S}_{ij}=\boldsymbol{\omega}^T\tanh(\boldsymbol{W}_q\boldsymbol{q}_{i}+\boldsymbol{W}_k\boldsymbol{k}_j+\boldsymbol{b})$
- Dot-Product Attention (Luong Attention,内积相似度):$\boldsymbol{S}_{ij}=\boldsymbol{q}_i^T\boldsymbol{k}_j$
- Bilinear Attention:$\boldsymbol{S}_{ij}=\boldsymbol{q}_i^T\boldsymbol{W}\boldsymbol{k}_j$,其中 $\boldsymbol{W}$ 是可学习的参数
- Scaled Dot-Product Attention:$\boldsymbol{S}_{ij}=\frac{\boldsymbol{q}_i^T\boldsymbol{k}_j}{\sqrt{d_k}}$($d_k$ 为 key 的维度)
可以简化地认为 attention 的本质是根据 query 与 key 间的匹配关系为一组 value 向量计算权重系数,随后使用这些权重系数为 value 向量进行加权求和,从而得到一个能够突出(对当前 query 位置而言重要的)相关信息的新表示向量。
而至于如何利用 attention、如何利用新表示向量,这就是上层的模型需要考虑的事了。
现在,我们可以给出 attention 的标准抽象形式了:
$$ \mathrm{Attention}(\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V})=\mathrm{Softmax}_{\text{over key}}(\boldsymbol{S})\boldsymbol{V},\ \ \ \ \boldsymbol{S}_{ij}=\mathrm{score}(\boldsymbol{q}_i,\boldsymbol{k}_j) \tag{30} $$也可以显式地写为加权和的形式,这样更符合上文的推导流程,也更能体现「注意力的本质是对 value 加权求和」:
$$ \boldsymbol{\mathrm{attention}}_{i}=\sum^m_{j=1}a_{ij}\boldsymbol{v}_j,\ \ \ \ a_{ij}=\frac{\exp(\boldsymbol{S}_{ij})}{\sum\limits^m_{l=1}\exp(\boldsymbol{S}_{il})} \tag{31} $$注:$\mathrm{Softmax}_{\text{over key}}$ 表示对每一个固定的 query 在所有 key 上进行归一化。更具体地,若令 $a_{ij}=\frac{\exp(\boldsymbol{S}_{ij})}{\sum\limits^m_{l=1}\exp(\boldsymbol{S}_{il})}$,则 $(a_{ij})=\mathrm{Softmax}_{\text{over key}}(\boldsymbol{S})\in\mathbb{R}^{n\times m}$,其中 $n,m$ 分别表示输入序列长度与 key 序列长度。
特别地,在划时代论文《Attention Is All You Need》中,所选取的 score 是 Scaled Dot-Product Attention,因此在这篇文献中,attention 的形式可以被更具体地写作一个在众多文章中频繁出现的式子:
$$ \mathrm{Attention}(\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V})=\mathrm{Softmax}\Bigg(\frac{\boldsymbol{Q}\boldsymbol{K}^T}{\sqrt{d_k}}\Bigg)\boldsymbol{V} \tag{32} $$若忽略线性投影 $\boldsymbol{Q}=\boldsymbol{X}_Q\boldsymbol{W}_Q,\boldsymbol{K}=\boldsymbol{X}_K\boldsymbol{W}_K,\boldsymbol{V}=\boldsymbol{X}_V\boldsymbol{W}_V$ 的开销,则计算 score 矩阵 $\boldsymbol{Q}\boldsymbol{K}^T$ 的时间复杂度为 $O(nmd_k)$,再与 $\boldsymbol{V}$ 相乘的时间复杂度为 $O(nmd_v)$,而 score 矩阵与 attention weight 矩阵本身均需要 $O(nm)$ 的空间复杂度。特别地,在 Self-Attention 的场景下有 $n=m$,若再将 $d_k,d_v$ 视为与模型维度 $d$ 同阶的量,则其时间复杂度可写为 $O(n^2d)$,空间复杂度可写为 $O(n^2)$。这也是 attention 在长序列场景下面临的核心计算瓶颈。
在抽象的 attention 中,$\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}$ 按下式计算
$$ \left\{\begin{aligned} &\boldsymbol{Q}=\boldsymbol{X}_{Q}\boldsymbol{W}_{Q}\\ &\\ &\boldsymbol{K}=\boldsymbol{X}_{K}\boldsymbol{W}_{K}\\ &\\ &\boldsymbol{V}=\boldsymbol{X}_{V}\boldsymbol{W}_{V} \end{aligned}\right. \tag{33} $$其中,
- $\boldsymbol{Q}\in\mathbb{R}^{n\times d_k}$:Query 矩阵,第 $i$ 行为位置索引为 $i$ 的 token 对应 query 向量的转置 $\boldsymbol{q}_i^T$
- $\boldsymbol{K}\in\mathbb{R}^{m\times d_k}$:Key 矩阵,第 $j$ 行为位置索引为 $j$ 的 token 对应 key 向量的转置 $\boldsymbol{k}_j^T$
- $\boldsymbol{V}\in\mathbb{R}^{m\times d_v}$:Value 矩阵,第 $k$ 行为位置索引为 $k$ 的 token 对应 value 向量的转置 $\boldsymbol{v}_k^T$
- $\boldsymbol{X}_{Q},\boldsymbol{X}_{K},\boldsymbol{X}_{V}$ 分别为 query 序列、key 序列、value 序列,在不同的 attention 设计中三者有不同的形式,例如在 Self-Attention 中三者均为同一个输入序列 $\boldsymbol{X}\in\mathbb{R}^{n\times d}$,且 $\boldsymbol{X}$ 的第 $i$ 行为 $\boldsymbol{x}_i^T$
- $\boldsymbol{W}_{Q}\in\mathbb{R}^{d\times d_k},\boldsymbol{W}_{K}\in\mathbb{R}^{d\times d_k},\boldsymbol{W}_{V}\in\mathbb{R}^{d\times d_v}$ 分别为 query 投影矩阵、key 投影矩阵、value 投影矩阵,通常都是可学习的参数矩阵
- $d_k$ 为 key 向量的维度,$n$ 为输入序列的长度,$m$ 为 key 序列与 value 序列的长度
可以看出,attention 本质是「表示的线性加权得到的新表示」,负责跨 token 间的信息交互与表示聚合,故 Transformer 在 attention 子层后通常会紧随添加 FFN 子层,其目的是「对新表示逐 token 进行非线性变换」以增强表达能力。通常而言 FFN 子层的计算量占大头。
上文所列举的 score 都是较为经典的设计,后来涌现出了不少它们的改进版本以及更多全新设计的 score。
值得一提的是,上文提到《Attention Is All You Need》选择了 Scaled Dot-Product Attention 而非 Dot-Product Attention,在一点在原文中给出了具体的解释:假设 $\forall i,j$,$\boldsymbol{q}_i,\boldsymbol{k}_j$ 的各分量均相互独立且 $\mathbb{E}(\boldsymbol{q}_i)=\mathbb{E}(\boldsymbol{k}_j)=\boldsymbol{0},\mathrm{Var}(\boldsymbol{q}_i)=\mathrm{Var}(\boldsymbol{k}_j)=\boldsymbol{1}$,则
$$ \mathbb{E}(\boldsymbol{q}_i^T\boldsymbol{k}_j)=\sum^{d_k}_{l=1}\mathbb{E}(q_{il}k_{jl})=\sum^{d_k}_{l=1}\big[\mathbb{E}(q_{il})\mathbb{E}(k_{jl})+\mathrm{Cov}(q_{il},k_{jl})\big]=0 \tag{34} $$$$ \mathrm{Var}(\boldsymbol{q}_i^T\boldsymbol{k}_j)=\underbrace{\sum^{d_k}_{l=1}\mathrm{Var}(q_{il}k_{jl})}_{=d_k}+\underbrace{2\sum_{u\lt t}\mathrm{Cov}(q_{iu}k_{ju},q_{it}k_{jt})}_{=0}=d_k \tag{35} $$这意味着 Dot-Product Attention 的方差为 $d_k$,当 $d_k$ 较大时 $\boldsymbol{q}_i^T\boldsymbol{k}_j$ 在数值上将表现得极不稳定,可能会在一个相当大的范围内散布,容易落入 Softmax 饱和区,造成梯度过小,这为优化算法带来了困难。
因此,《Attention Is All You Need》考虑标准化后的 Scaled Dot-Product Attention,即 $\frac{\boldsymbol{q}_i^T\boldsymbol{k}_j}{\sqrt{d_k}}$,这样就构造出了一个均值为 0、方差为 1 的无量纲量,不随环境改变而变化。
参考文献:
- Vaswani, Ashish, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser and Illia Polosukhin. “Attention is All you Need.” Neural Information Processing Systems (2017).
Attention 的反向传播算法
这里推导单头无 mask 的 Scaled Dot-Product Attention 的梯度,以便从反向传播的角度进一步理解 attention。记损失函数为 $\mathcal{L}$,有
$$ \boldsymbol{A}\triangleq\mathrm{Softmax}_{\text{over key}}(\boldsymbol{S}),\ \ \ \ \boldsymbol{S}=\frac{\boldsymbol{Q}\boldsymbol{K}^T}{\sqrt{d_k}},\ \ \ \ \boldsymbol{O}\triangleq\mathrm{Attention}(\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V})=\boldsymbol{A}\boldsymbol{V} \tag{36} $$记上游梯度
$$ \boldsymbol{G}\triangleq\frac{\partial\mathcal{L}}{\partial\boldsymbol{O}} \tag{37} $$首先,由矩阵乘法 $\boldsymbol{O}=\boldsymbol{A}\boldsymbol{V}$ 可知
$$ \frac{\partial\mathcal{L}}{\partial\boldsymbol{V}}=\boldsymbol{A}^T\boldsymbol{G},\ \ \ \ \frac{\partial\mathcal{L}}{\partial\boldsymbol{A}}=\boldsymbol{G}\boldsymbol{V}^T \tag{38} $$接下来对按行进行的 Softmax 求导。为避免矩阵的「第 $i$ 行」与列向量 Jacobian 记号混用,对于任意固定的 query 位置 $i$,记第 $i$ 行 score 与 attention weight 分别为 $\boldsymbol{s}_i^T,\boldsymbol{a}_i^T\in\mathbb{R}^{1\times m}$,其中 $\boldsymbol{s}_i,\boldsymbol{a}_i\in\mathbb{R}^{m\times1}$ 是对应的列向量,满足
$$ \boldsymbol{a}_i=\mathrm{Softmax}(\boldsymbol{s}_i) \tag{39} $$由 Softmax 的 Jacobian 形式
$$ \frac{\partial\boldsymbol{a}_i}{\partial\boldsymbol{s}_i}=\mathrm{diag}(\boldsymbol{a}_i)-\boldsymbol{a}_i\boldsymbol{a}_i^T \tag{40} $$可知
$$ \frac{\partial\mathcal{L}}{\partial\boldsymbol{s}_i} =\left(\frac{\partial\boldsymbol{a}_i}{\partial\boldsymbol{s}_i}\right)^T\frac{\partial\mathcal{L}}{\partial\boldsymbol{a}_i} =\Big(\mathrm{diag}(\boldsymbol{a}_i)-\boldsymbol{a}_i\boldsymbol{a}_i^T\Big)\frac{\partial\mathcal{L}}{\partial\boldsymbol{a}_i} =\boldsymbol{a}_i\odot\Bigg(\frac{\partial\mathcal{L}}{\partial\boldsymbol{a}_i}-\bigg(\boldsymbol{a}_i^T\frac{\partial\mathcal{L}}{\partial\boldsymbol{a}_i}\bigg)\boldsymbol{1}_m\Bigg) \tag{41} $$其中 $\boldsymbol{1}_m\in\mathbb{R}^{m\times1}$ 为全 1 向量。若记 $\boldsymbol{r}\in\mathbb{R}^{n\times1}$,其第 $i$ 个分量为
$$ r_i\triangleq\boldsymbol{a}_i^T\frac{\partial\mathcal{L}}{\partial\boldsymbol{a}_i}=\sum_{j=1}^{m}\frac{\partial\mathcal{L}}{\partial A_{ij}}A_{ij} \tag{42} $$则把各行结果转回矩阵形式,可将其合并写为
$$ \boxed{\frac{\partial\mathcal{L}}{\partial\boldsymbol{S}}=\boldsymbol{A}\odot\Bigg(\frac{\partial\mathcal{L}}{\partial\boldsymbol{A}}-\boldsymbol{r}\boldsymbol{1}_m^T\Bigg)} \tag{43} $$再由
$$ \boldsymbol{S}=\frac{\boldsymbol{Q}\boldsymbol{K}^T}{\sqrt{d_k}} \tag{44} $$可得
$$ \boxed{\frac{\partial\mathcal{L}}{\partial\boldsymbol{Q}}=\frac{1}{\sqrt{d_k}}\frac{\partial\mathcal{L}}{\partial\boldsymbol{S}}\boldsymbol{K}},\ \ \ \ \boxed{\frac{\partial\mathcal{L}}{\partial\boldsymbol{K}}=\frac{1}{\sqrt{d_k}}\Bigg(\frac{\partial\mathcal{L}}{\partial\boldsymbol{S}}\Bigg)^T\boldsymbol{Q}} \tag{45} $$最后,由
$$ \boldsymbol{Q}=\boldsymbol{X}_Q\boldsymbol{W}_Q,\ \ \ \ \boldsymbol{K}=\boldsymbol{X}_K\boldsymbol{W}_K,\ \ \ \ \boldsymbol{V}=\boldsymbol{X}_V\boldsymbol{W}_V \tag{46} $$便得到参数梯度
$$ \boxed{\frac{\partial\mathcal{L}}{\partial\boldsymbol{W}_Q}=\boldsymbol{X}_Q^T\frac{\partial\mathcal{L}}{\partial\boldsymbol{Q}}},\ \ \ \ \boxed{\frac{\partial\mathcal{L}}{\partial\boldsymbol{W}_K}=\boldsymbol{X}_K^T\frac{\partial\mathcal{L}}{\partial\boldsymbol{K}}},\ \ \ \ \boxed{\frac{\partial\mathcal{L}}{\partial\boldsymbol{W}_V}=\boldsymbol{X}_V^T\frac{\partial\mathcal{L}}{\partial\boldsymbol{V}}} \tag{47} $$若还需继续向输入序列反向传播,则有
$$ \frac{\partial\mathcal{L}}{\partial\boldsymbol{X}_Q}=\frac{\partial\mathcal{L}}{\partial\boldsymbol{Q}}\boldsymbol{W}_Q^T,\ \ \ \ \frac{\partial\mathcal{L}}{\partial\boldsymbol{X}_K}=\frac{\partial\mathcal{L}}{\partial\boldsymbol{K}}\boldsymbol{W}_K^T,\ \ \ \ \frac{\partial\mathcal{L}}{\partial\boldsymbol{X}_V}=\frac{\partial\mathcal{L}}{\partial\boldsymbol{V}}\boldsymbol{W}_V^T \tag{48} $$若处于 Self-Attention 的场景下,只需进一步令 $\boldsymbol{X}_Q=\boldsymbol{X}_K=\boldsymbol{X}_V=\boldsymbol{X}$ 即可。
由此也能看出一个有趣的事实,在 Scaled Dot-Product Attention 的例子下有
- $\boldsymbol{Q}$ 的梯度依赖所有 $\boldsymbol{K}$ 的信息;
- $\boldsymbol{K}$ 的梯度依赖所有 $\boldsymbol{Q}$ 的信息;
- $\boldsymbol{V}$ 的梯度的任何分量均通过权重 $\boldsymbol{A}$ 间接依赖全局 query。
这意味着
- 每个 query 与所有 key 交互;
- 每个 key 与所有 query 交互;
- 每个 value 的更新受所有 query 影响。
基于上述推导我们可以得出一个重要结论:Attention 中任意两个 token 间都至少存在一条 $O(1)$ 常数长度的梯度路径(相比之下,RNN 为 $O(n)$)。也就是说,Scaled Dot-Product Attention 在反向传播时建立了 token 间的全连接梯度路径,使得 token 能够显式随机访问以动态召回其他 token,这是基于 attention 的 Transformer 能在相当程度上解决长期依赖问题的一个重要原因。
基础 Attention 结构范式
上文给出了 attention 的一般数学形式,根据 $\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}$ 在来源关系上的不同,可以区分出若干 attention 的基本结构范式。
Cross-Attention
如果 query 序列 $\boldsymbol{X}_{Q}$ 与 key 序列 $\boldsymbol{X}_{K}$ 不一致,则称为 Cross-Attention。
无论是哪种结构范式,大多数情况下,key 序列 $\boldsymbol{X}_K$ 与 value 序列 $\boldsymbol{X}_V$ 都是一致的。从语义上讲,key 序列代表「为 query 提供什么信息」,而 value 序列代表「本身表示什么内容」,二者通常是同一语义,因此便不难理解为何二者通常均对应同一序列了。
在 Seq2Seq 上被应用的 Bahdanau Attention 就是一种典型的 Cross-Attention,回到 Bahdanau Attention 的关键公式
$$ \boldsymbol{c}_t=\sum^{T}_{i=1}\alpha_{t,i}\boldsymbol{h}_i,\ \ \ \ \mathrm{score}(\boldsymbol{s}_{t-1},\boldsymbol{h}_j)=\boldsymbol{\omega}^T\tanh(\boldsymbol{W}_s\boldsymbol{s}_{t-1}+\boldsymbol{W}_h\boldsymbol{h}_j+\boldsymbol{b}_a) \tag{49} $$可见,对 Bahdanau Attention 而言 key 与 value 均为 encoder 隐状态 $\boldsymbol{h}$,query 为 decoder 隐状态 $\boldsymbol{s}$,而 encoder 与 decoder 的输入序列并不一致,因此 Bahdanau Attention 是一种 Cross-Attention。
由 Facebook AI 团队在 2020 年发布的 RAG(Retrieval-Augmented Generation)技术中所使用的 attention 也是一种典型的 Cross-Attention。这里不深入分析 RAG 的实现原理,只从直觉上就很容易推断:我们希望利用文本 A 作为依据在知识库中召回(retrieve)相关文本 B,当然是让 A(输入 decoder 后得到的隐状态输出)作为 query,让 B(的文档表示)作为 key 与 value,这是因为 A 是查询者,提供要查询的信息;B 是被查询者,提供被查询的内容。
后来的一些 RAG 改进实现已经不属于 Cross-Attention 体系了。
参考文献:
- Lewis, Patrick, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Kuttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel and Douwe Kiela. “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.” ArXiv abs/2005.11401 (2020): n. pag.
Self-Attention
如果 query 序列 $\boldsymbol{X}_{Q}$ 与 key 序列 $\boldsymbol{X}_{K}$ 一致,则称为 Self-Attention。Transformer 所使用的 attention 就是典型的 Self-Attention。在大多数情况下,Self-Attention 中 $\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}$ 的来源序列均为同一个输入序列 $\boldsymbol{X}$。
$$ \left\{\begin{aligned} &\boldsymbol{Q}=\boldsymbol{X}\boldsymbol{W}_{Q}\\ &\\ &\boldsymbol{K}=\boldsymbol{X}\boldsymbol{W}_{K}\\ &\\ &\boldsymbol{V}=\boldsymbol{X}\boldsymbol{W}_{V} \end{aligned}\right. \tag{50} $$Self-Attention 的一个重要特点是序列中的每一个位置都可以直接访问序列中的所有其他位置(在不考虑可见性约束的情况下),而不必像 RNN-based 的结构那样必须通过隐状态在时间维度上逐步而间接地传递信息。换言之,序列中的每个 token 既是查询者,同时也是被查询者,并且任意两个 token 间的信息交互都可以在单层 attention 内直接完成。这是高效的实践,也是 Transformer 能并行建模长程依赖的重要原因。
若不额外施加约束,则第 $i$ 个位置在计算时能够访问整个序列的全部位置,这种结构常见于 encoder 或双向语言模型。但对于自回归生成任务,我们必须设法阻止当前位置访问未来位置,否则将造成标签泄漏。最常见的做法是引入因果掩码(Causal Mask)$\boldsymbol{M}_{\text{causal}}$,其中
$$ (\boldsymbol{M}_{\text{causal}})_{ij}=\left\{ \begin{aligned} &0,&&\text{if }j\leqslant i\\ &-\infty,&&\text{if }j>i \end{aligned} \right. \tag{51} $$以 Scaled Dot-Product Score 为例,有
$$ \mathrm{MaskedSelfAttention}(\boldsymbol{X};\boldsymbol{M}_{\text{causal}})=\mathrm{Softmax}\Bigg(\frac{\boldsymbol{Q}\boldsymbol{K}^T}{\sqrt{d_k}}+\boldsymbol{M}_{\text{causal}}\Bigg)\boldsymbol{V} \tag{52} $$由于 $\exp(-\infty)=0$,未来位置经 Softmax 后的权重恒为 0,于是第 $i$ 个 token 便仅能关注到自身及其之前的位置。以 GPT 为代表的 decoder-only LLM 在训练和推理阶段所使用的正是这种 Masked Self-Attention。
除此之外还有许多掩码的实现。更一般地,若对第 $i$ 个位置规定一个可见位置集合 $\Omega_i\subseteq\{1,2,\cdots,n\}$,则可定义
$$ (\boldsymbol{M})_{ij}=\left\{ \begin{aligned} &0,&&\text{if }j\in\Omega_i\\ &-\infty,&&\text{if }j\notin\Omega_i \end{aligned}\right. \tag{53} $$以 Scaled Dot-Product Score 为例,有
$$ \mathrm{MaskedSelfAttention}(\boldsymbol{X};\boldsymbol{M})=\mathrm{Softmax}\Bigg(\frac{\boldsymbol{Q}\boldsymbol{K}^T}{\sqrt{d_k}}+\boldsymbol{M}\Bigg)\boldsymbol{V} \tag{54} $$例如 Local Window Attention,通过令 $\Omega_i=[i-w,i+w]$,使得模型针对第 $i$ 个位置仅关注位置区间 $[i-w,i+w]$ 内的 token。在长文本、时序序列与视觉 Transformer 场景下,这种做法能够降低计算量、控制感受野,或是向模型显式注入某种结构先验。
因果掩码不仅在理论上能避免标签泄露的问题,同时还在工程上带来了一个重要的影响:因果掩码的加入,使得 $\boldsymbol{\mathrm{attention}}_{i}$ 只受 $i$ 及其之前位置的影响,这表现为 attention 是单向的,因为对 $i$ 而言 $i$ 以后的位置都被「屏蔽」了。在后文将介绍,这是自回归的 decoder 能使用 KV Cache 实现 incremental decoding 并降低单步 attention 计算量的基石和前提之一。
这真的相当重要!没有因果掩码,注意力将会是双向的,历史位置的表示会随未来 token 的引入而发生变化,因而 KV Cache 将无法支持标准的 incremental decoding。对于长度为 $t$ 的前缀,若只讨论单层 Self-Attention 的主导项,则每一步都需对整个前缀重新计算一次 attention,单步时间复杂度为 $O(t^2d)$;而在因果掩码与 KV Cache 同时成立时,利用 incremental decoding,我们仅需对新位置与历史 $\boldsymbol{K},\boldsymbol{V}$ 的交互进行一次计算,单步时间复杂度可降至 $O(td)$。在 Transformer 章节中将详细说明这一点。
从原理上看,Self-Attention 对输入序列的顺序是等变(equivariant)的,这导致若直接交换输入 token 的排列顺序而不额外提供任何位置信息,Self-Attention 本身并不能区分出这种顺序变化。即,模型虽然能够学习到 token 与 token 间的相关性,却无法学习到 token 的顺序关系。毕竟,「我 喜欢 你」和「你 喜欢 我」是完全相反的顺序,若不引入位置编码,模型可能就无法学习到这两个短句在表达含义上的区别。
为解决这个问题,LLM 通常会在 Self-Attention 中引入位置编码(Position Encoding)以将顺序信息编码进输入表示中,从而使得模型能够学习不同 token 间的顺序关系。
一种简单的位置编码实现是将第 $i$ 个位置对应的位置向量 $\boldsymbol{p}_i$ 与 token embedding $\boldsymbol{e}_i$ 相加,进而得到真正送入 Transformer 的输入表示
$$ \boldsymbol{x}_i=\boldsymbol{e}_i+\boldsymbol{p}_i \tag{55} $$于是输入矩阵便可写作 $\boldsymbol{X}=\boldsymbol{E}+\boldsymbol{P}$,其中 $\boldsymbol{E}$ 表示 token embedding 矩阵,$\boldsymbol{P}$ 表示位置编码矩阵。这样一来,后续由 $\boldsymbol{X}$ 线性投影得到的 $\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}$ 便天然地携带了位置信息。
位置编码有许多种具体设计,其中最经典的是《Attention Is All You Need》所使用的 Fixed Sinusoidal Positional Encoding。若记模型表示维度为 $d$,并记 $\boldsymbol{p}_i$ 的第 $j$ 个分量为 $\boldsymbol{p}_i^{(j)}$,则
$$ \forall l\in\mathbb{N},\ \ \boldsymbol{p}_i^{(j)}=\left\{\begin{aligned}&\sin\Bigg(\frac{i}{10000^{\frac{j}{d}}}\Bigg),&&j=2l\\&\\&\cos\Bigg(\frac{i}{10000^{\frac{j-1}{d}}}\Bigg),&&j=2l+1\end{aligned}\right. \tag{56} $$后来的大量工作则进一步提出了可学习位置编码、相对位置编码、RoPE 等改进形式。它们的共同目标均是为原本对顺序不敏感的 Self-Attention 注入位置信息,从而使模型不仅能认识到「哪些 token 相关」,还认识到「这些 token 以什么顺序相关」。
Multi-Head Attention
若 attention 的实现只有一组投影矩阵 $\boldsymbol{W}_Q,\boldsymbol{W}_K,\boldsymbol{W}_V$,则称为 Single-Head Attention。将多个 Single-Head Attention 并行地联合起来,即 attention 内有多组投影矩阵,则称为 Multi-Head Attention。《Attention Is All You Need》中,所使用的正是 Multi-Head Attention。
Cross-Attention 与 Self-Attention 是相对立的,Single-Head Attention 则与 Multi-Head Attention 是相对立的。
由于只有一组投影矩阵,因此 Single-Head Attention 也只会得到一个权重矩阵,这意味着所有 token 间的交互都必须通过同一套相似度度量与同一个表示子空间完成,这样的模型表达能力往往较为局限。Multi-Head Attention 通过并行地计算多头 attention,不同的 head 在不同的线性子空间中有能力学习到不同类型的相关性,包括长程指代、语法依赖与语义相关等若干关系。
假设 Multi-Head Attention 共有 $h$ 个 head,对于第 $r$ 个 head,分别引入一组独立的参数矩阵 $\boldsymbol{W}^{(r)}_{Q},\boldsymbol{W}^{(r)}_{K},\boldsymbol{W}^{(r)}_{V}$,有
$$ \left\{\begin{aligned} &\boldsymbol{Q}^{(r)}=\boldsymbol{X}_{Q}\boldsymbol{W}^{(r)}_{Q}\\ &\\ &\boldsymbol{K}^{(r)}=\boldsymbol{X}_{K}\boldsymbol{W}^{(r)}_{K}\\ &\\ &\boldsymbol{V}^{(r)}=\boldsymbol{X}_{V}\boldsymbol{W}^{(r)}_{V} \end{aligned}\right. \tag{57} $$第 $r$ 个 head 的输出为
$$ \mathrm{head}_r=\mathrm{Attention}\big(\boldsymbol{Q}^{(r)},\boldsymbol{K}^{(r)},\boldsymbol{V}^{(r)}\big)=\mathrm{Softmax}\Bigg(\frac{\boldsymbol{Q}^{(r)}(\boldsymbol{K}^{(r)})^T}{\sqrt{d_k}}\Bigg)\boldsymbol{V}^{(r)} \tag{58} $$将所有 head 的结果按特征维拼接后,再经一次线性变换,即可得到 Multi-Head Attention 的最终输出
$$ \mathrm{MultiHead}(\boldsymbol{X}_{Q},\boldsymbol{X}_{K},\boldsymbol{X}_{V})=\mathrm{Concat}(\mathrm{head}_1,\mathrm{head}_2,\cdots,\mathrm{head}_h)\boldsymbol{W}_{O} \tag{59} $$其中 $\boldsymbol{W}_{O}$ 为输出投影矩阵。
若模型隐状态维度(模型中每个位置 token 对应的向量的维度)为 $d$,通常取
$$ d_k=d_v=\frac{d}{h} \tag{60} $$此时每个 head 只负责总表示空间中的一个子空间,将所有 head 拼接后便能够得到与原模型维度 $d$ 相匹配的表示空间。
若序列长度为 $n$,则单个 head 的 attention 计算复杂度约为 $O\big(n^2(\frac{d}{h})\big)$;将 $h$ 个 head 并行合并后,总复杂度仍保持在 $O(n^2d)$ 的量级。因此,在固定模型维度 $d$ 的前提下,Multi-Head Attention 相较于 Single-Head Attention 的主要收益在于表示能力的提升,而非渐近复杂度阶的降低。
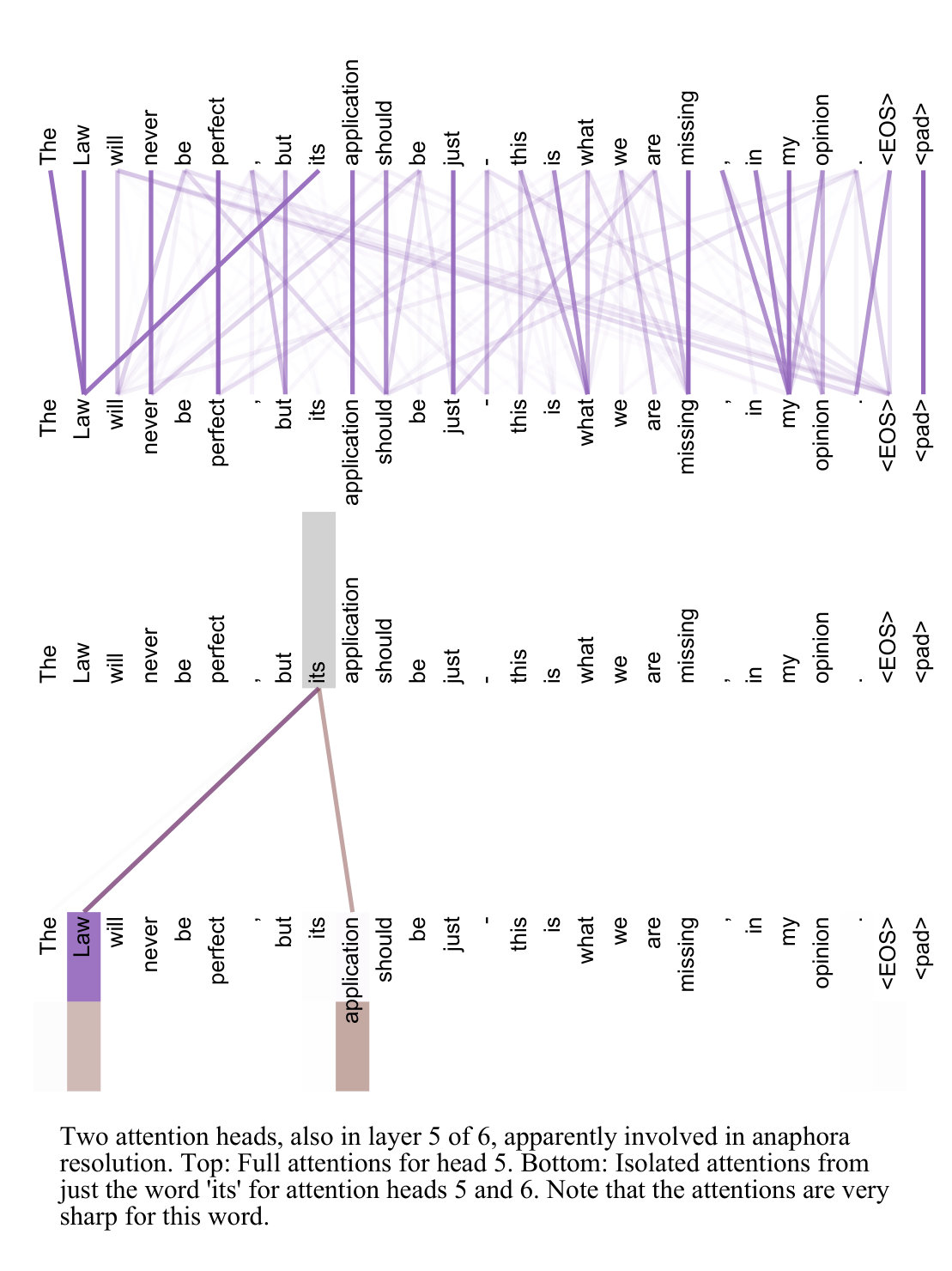
在经典文献《Attention Is All You Need》中,原作者曾给出过如下可视化示意图,意在表明某些 head 会专门学习「代词 → 先行词」的指代关系(注意:这属于跨位置的语义绑定,而非简单的局部语法关系),并且 attention 值十分突出,意味着这并非随机行为。更进一步地,这体现出多个 head 存在功能分化的现象,部分 head 可能专门负责捕获某种深刻关系。下图中,上半部分为某个 head 的完整 attention 分布,下半部分为该 head 对 token「its」 的 attention 连接。
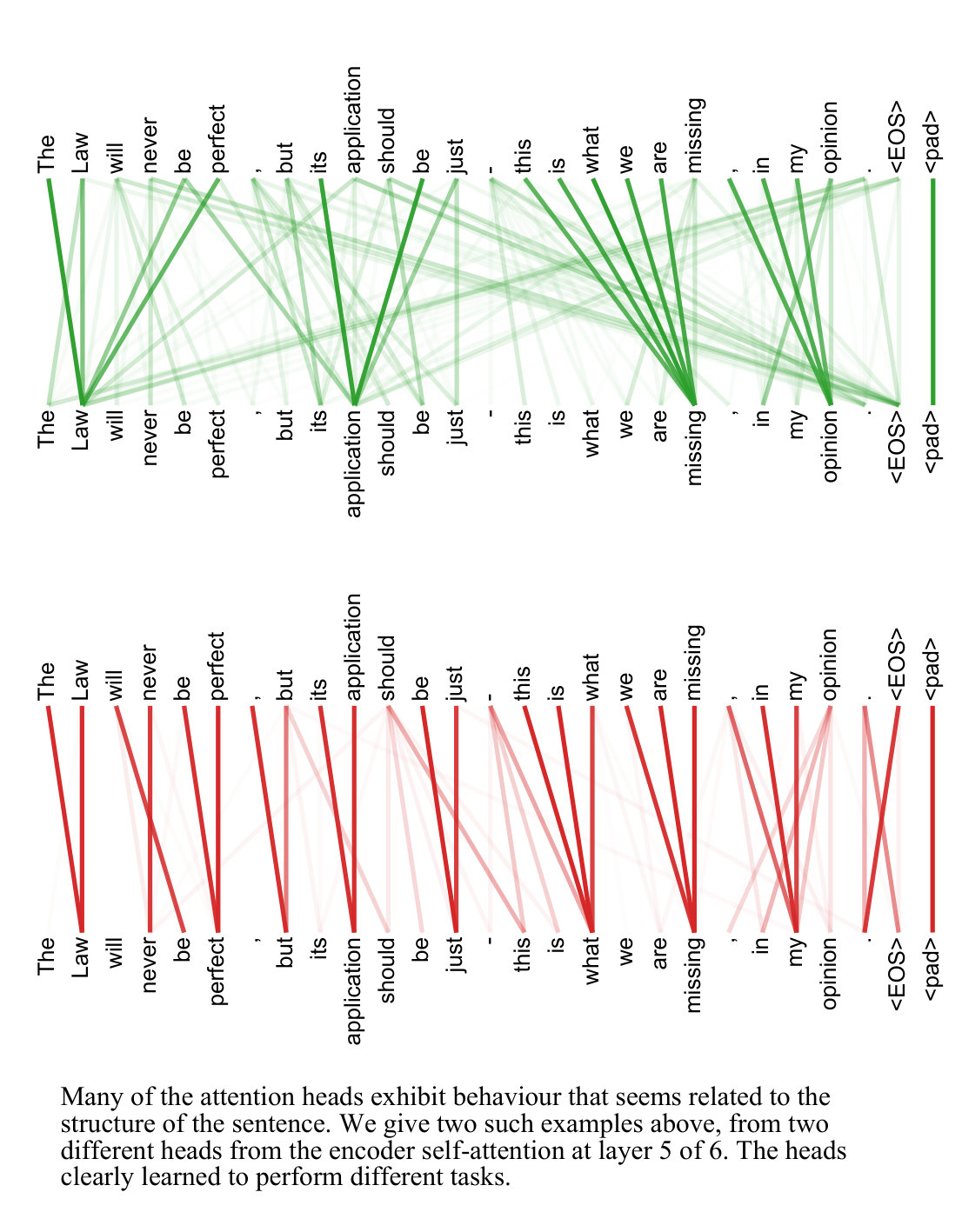
原作者在文献中也给出过另一张可视化示意图,如下图所示,这更加直观地体现了不同 head 能够学习到不同的句法结构。下图中,上半部分绿色标记的 head 更多在捕获语义或结构上的关键节点,例如主语、宾语与从句关键词等,而下半部分红色标记的 head 则主要在关注局部语法,侧重于 token 自身及其相邻 token。
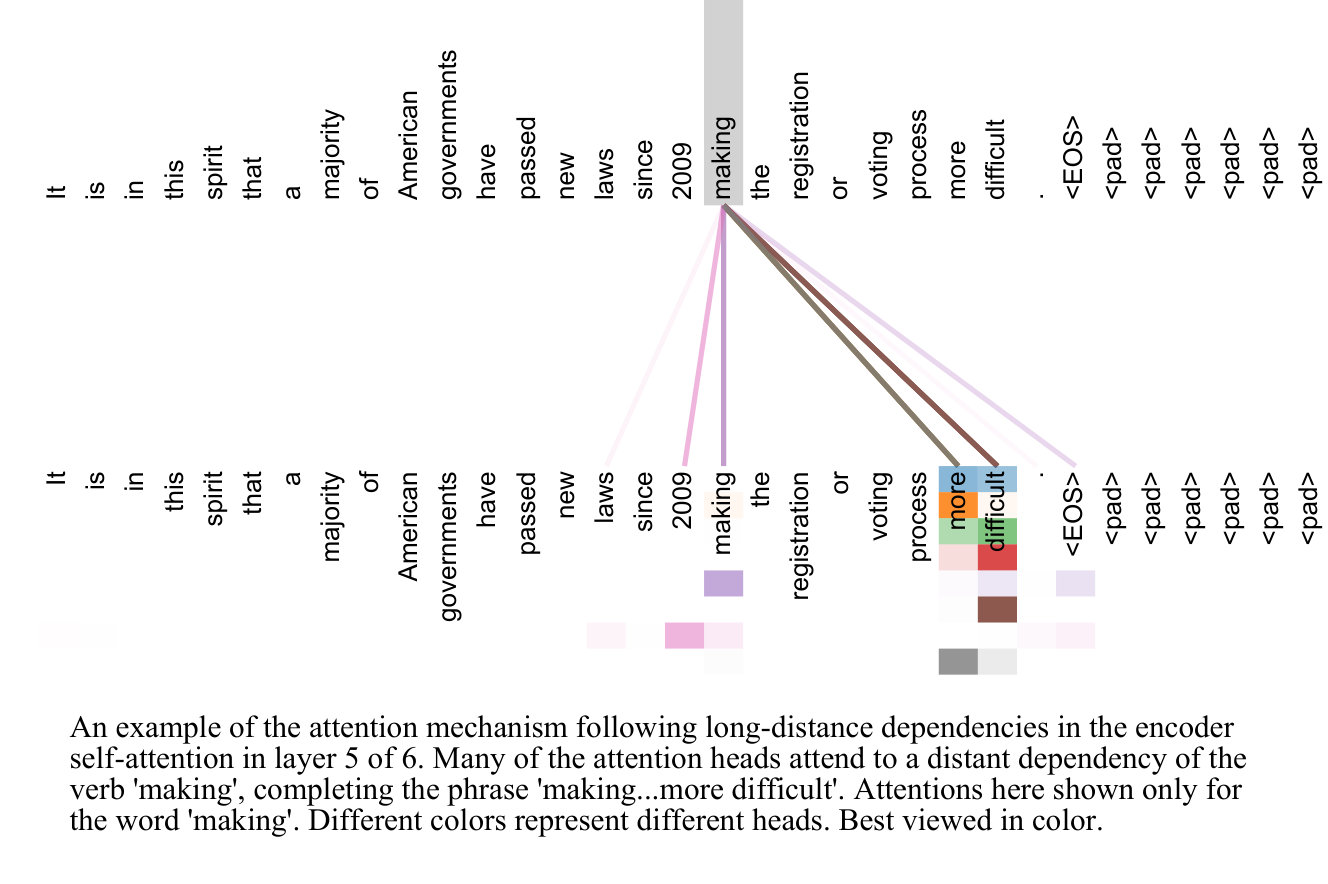
除此之外,文献中还给出了一张可视化示意图,如下图所示,这直观地表明 Transformer 能够学习到长距离语法依赖,因为有多个 head(不同颜色标记)都自 token「making」建立了至不同距离的不同 token 的连接。不难看出,这实际上表示的是动词与补语间的结构关系。
附:一个简单的计算示例
让我们来构造一个简单的演示案例,以更直观地感受 Self-Attention 是如何计算的。
假设现在我们有三个 token:["I", "love", "U"],分别对应 3 维的 embedding 向量 $[1,0,0]$、$[0,1,1]$ 与 $[-1,0,0]$,则 batch 大小为 1 的输入矩阵为
模型需要学习三个权重矩阵 $\boldsymbol{W}_{Q},\boldsymbol{W}_{K},\boldsymbol{W}_{V}$,假设分别为
$$ \boldsymbol{W}_{Q}=\left(\begin{matrix} -1&0&1\\ 0&1&0\\ 1&0&-1 \end{matrix}\right)\quad\boldsymbol{W}_{K}=\left(\begin{matrix} 1&0&0\\ 0&1&1\\ 0&1&1 \end{matrix}\right)\quad\boldsymbol{W}_{V}=\left(\begin{matrix} 1&0&0\\ 0&-2&0\\ 0&0&2 \end{matrix}\right) \tag{62} $$分别计算 $\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}$,有
$$ \boldsymbol{Q}=\boldsymbol{XW}_{Q}=\begin{pmatrix} -2 & 0 & 2 \\ 0 & 1 & 0 \\ 0 & 1 & 0 \end{pmatrix} \tag{63} $$$$ \boldsymbol{K}=\boldsymbol{XW}_{K}=\begin{pmatrix} 1 & -1 & -1 \\ 0 & 1 & 1 \\ 0 & 1 & 1 \end{pmatrix} \tag{64} $$$$ \boldsymbol{V}=\boldsymbol{XW}_{V}=\begin{pmatrix} 1 & 0 & -2 \\ 0 & -2 & 0 \\ 0 & -2 & 0 \end{pmatrix} \tag{65} $$现在计算各 token 间的 attention score,考虑 Scaled Dot-Product Attention,则
$$ \boldsymbol{S}=\frac{1}{\sqrt{3}}\boldsymbol{QK}^T=\begin{pmatrix} -\frac{2}{\sqrt{3}} & \frac{4}{\sqrt{3}} & \frac{4}{\sqrt{3}} \\ 0 & \frac{1}{\sqrt{3}} & \frac{1}{\sqrt{3}} \\ 0 & \frac{1}{\sqrt{3}} & \frac{1}{\sqrt{3}} \end{pmatrix} \tag{66} $$按 $\boldsymbol{S}$ 的行做 Softmax 归一化,近似有
$$ \hat{\boldsymbol{S}}\approx\begin{pmatrix} 0.015 & 0.492 & 0.492 \\ 0.219 & 0.390 & 0.390 \\ 0.219 & 0.390 & 0.390 \end{pmatrix} \tag{67} $$计算 attention,有
$$ \mathrm{Attentnon}=\hat{\boldsymbol{S}}\boldsymbol{V}=\begin{pmatrix} 0.015 & -1.968 & -0.03 \\ 0.219 & -1.56 & -0.438 \\ 0.219 & -1.56 & -0.438 \end{pmatrix} \tag{68} $$再次强调,$\mathrm{Attentnon}$ 是 $\boldsymbol{V}$ 按 $\hat{\boldsymbol{S}}$ 的加权和。
对于 Transformer 而言,下一步是将 $\mathrm{Attentnon}$ 作为 FNN 子层的输入,得到输出。然后,再将输出作为下一层的输入,重复操作——详见下一章。
Transformer
经典 Encoder-Decoder 架构
至此,Transformer 所需的关键部件其实已经齐备:attention 的一般形式给出了统一的计算框架,Self-Attention 使序列中任意两个位置能够直接交互,Multi-Head Attention 提升了模型的表示能力,位置编码则为原本对顺序不敏感的 attention 注入了位置信息。本质上,所谓 Transformer 正是将这些部件按 Encoder–Decoder 的方式组织拼接起来,同时彻底抛弃 RNN。
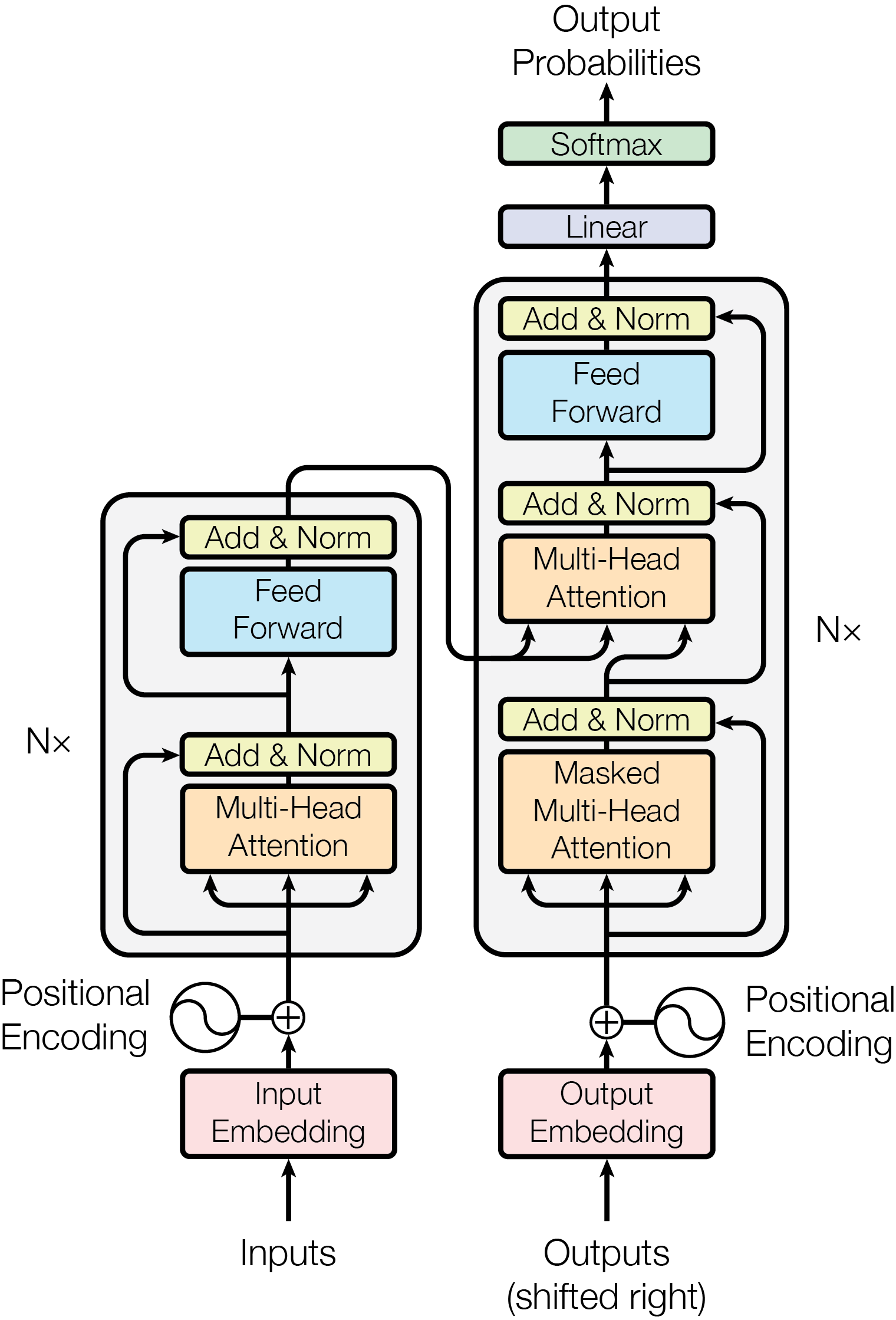
在接下来的两个小节中,我们将介绍《Attention Is All You Need》中所提出的首个 Transformer 模型(典型 Encoder-Decoder 架构),该模型可被视为经典 Seq2Seq 的改进或升级,依然属于 Encoder-Decoder 架构。相较于经典 Seq2Seq,这一模型不再依赖 RNN 逐步传递隐状态,而是以 attention 为核心构造 encoder 与 decoder,从而在获得更强的并行计算能力的同时也拥有更灵活的长程依赖建模能力。因此才有所谓的「Attention is all you need」——我们并不需要 RNN,只需要 attention 便能完成数据建模,而且还能取得更好的效果。这在 2017 年是极具开创性的工作。

如上图所示,该模型的 encoder 与 decoder 都不再含有 RNN,而是由若干个结构相同的层堆叠而成。在原论文中,encoder 与 decoder 各自堆叠了 6 层,分别称为编码器层与解码器层。
在经典文献《Attention Is All You Need》中,原作者给出的是如下示意图。该示意图相对精简,没有刻画出 dropout 等子结构。
Encoder
首先讨论 encoder。Encoder 的输入是完整源序列的 token embedding 矩阵经位置编码后所得到输入表示
$$ \boldsymbol{X}^{(0)}=\boldsymbol{E}+\boldsymbol{P} \tag{69} $$其中 $\boldsymbol{E}$ 为源序列的 token embedding 矩阵,$\boldsymbol{P}$ 为位置编码矩阵。Encoder 共包含六个子层(编码器层),并且每一层都以上一层的输出作为当前层输入,每个编码器层又可以按前馈顺序被进一步分解为两个子层:
- Multi-Head Self-Attention 子层;
- 逐位置独立作用的 FFN 子层。
在原论文的实现中,每一个子层外都包裹着残差连接(Residual Connection)与层归一化(Layer Normalization)。记第 $l$ 层 encoder 的输入为 $\boldsymbol{X}^{(l-1)}$,$1\leqslant l\leqslant 6$,则编码器层的每一层计算的数学表示为
$$ \tilde{\boldsymbol{X}}^{(l)}=\mathrm{LayerNorm}\big(\underbrace{\boldsymbol{X}^{(l-1)}}_{\text{Residual}}+\mathrm{MultiHeadAttention}(\boldsymbol{X}^{(l-1)},\boldsymbol{X}^{(l-1)},\boldsymbol{X}^{(l-1)})\big) \tag{70} $$$$ \boldsymbol{X}^{(l)}=\mathrm{LayerNorm}\big(\underbrace{\tilde{\boldsymbol{X}}^{(l)}}_{\text{Residual}}+\mathrm{FFN}(\tilde{\boldsymbol{X}}^{(l)})\big) \tag{71} $$其中 $\mathrm{FFN}$ 通常由两层线性变换与中间的逐元素非线性激活函数构成,并且对每一个位置的 token 独立地作用,即
$$ \mathrm{FFN}(\tilde{\boldsymbol{X}}^{(l)}) =\varphi(\tilde{\boldsymbol{X}}^{(l)}\boldsymbol{W}_1+\boldsymbol{b}_1)\boldsymbol{W}_2+\boldsymbol{b}_2 \tag{72} $$这里残差连接的目的是保留子层输入的原始信息,同时为梯度提供一条更直接的传播路径,缓解深层堆叠时的优化困难;层归一化的作用则是对每个位置上的表示作归一化处理,使得不同层之间的数值尺度相对稳定,减轻训练过程中参数的数值不稳定现象。二者相互配合,是 Transformer 能够稳定堆叠多层结构的重要原因。
在 encoder 中,由于 $\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}$ 均来自同一个输入序列,因此这里使用的 attention 是典型的 Self-Attention。
若源序列长度为 $n$、模型维度为 $d$、FFN 的中间层维度为 $d_{\text{ff}}$,则单个编码器层的计算复杂度大致可分解为两部分:Multi-Head Self-Attention 子层的 $O(n^2d)$ 与 FFN 子层的 $O(ndd_{\text{ff}})$。因此,当序列较长时,attention 的二次复杂度往往是 encoder 的主要计算瓶颈。
尽管 encoder 包含 6 层编码器层,但从单层的结构上看,第一层、中间层与最后一层的编码器并无结构上的区别,它们只是参数各自独立并且输入输出所处的抽象层次不同。
经过 6 层编码器层后,最终 encoder 将输出一组上下文表示 $\boldsymbol{X}^{(6)}$,我们将其称为 Encoder Memory,这组表示稍后将同时作为 decoder 中 Cross-Attention 的 key 与 value。可见,encoder 依然是「信息提取者」的角色,能够「总结」上下文。
这暗示了 decoder 包含 Cross-Attention。实际上,原论文中的 encoder 使用的是纯粹的 Self-Attention,而 decoder 同时使用了 Causal Masked Self-Attention 与 Cross-Attention(Encoder–Decoder Attention);二者均应用了 Multi-Head Attention。
要特别说明的是,训练时与推理时 encoder 均仅并行计算一次,由 decoder 多次进行自回归以生成全部输出。因此若考虑 Encoder-Decoder LLM,则 encoder 只会计算一次输入 prompt 与上下文,不会在随后 decoder 每一次自回归生成 token 输出时都进行重复计算。
但现在许多 LLM 已经没有了 encoder 的设计,只有 decoder 了。后文会展开这一点。
Decoder 与 KV Cache
接着讨论 decoder。Decoder 的输入在训练与推理时略有不同,为了在训练时达到推理输出的等价效果,需要对目标序列显式右移。所谓右移,设训练时原始的目标序列为 $(y_1,y_2,\cdots,y_T)$,我们在目标序列头部插入起始标记 token $\langle BOS\rangle$ 并移除最后一个 token,便得到了右移后的序列 $\big(\langle BOS\rangle,y_1,y_2,\cdots,y_{T-1}\big)$,其中原本的最后一个 token $y_T$ 用于计算训练时的误差以便反向传播梯度并使用优化算法更新参数。
$y_T$ 也可以是终止标记 token $\langle EOS\rangle$。
这种做法本质上就是 Transformer 在训练阶段所采用的 Teacher Forcing:在预测第 $t$ 个 token 时,decoder 所接收到的是真实的前缀序列 $\big(\langle BOS\rangle,y_1,y_2,\cdots,y_{t-1}\big)$,而非模型在前面各步自行生成的 token。这样做的好处是能够并行地计算所有位置上的条件概率分布,并显著提升训练的稳定性与效率。
记 $\boldsymbol{E}_{\text{target}}$ 为输入目标序列(对于训练时,为右移后的原始目标序列;对于推理时,为自回归输入)、$\boldsymbol{P}_{\text{target}}$ 为位置编码矩阵,则 decoder 的输入为
$$ \boldsymbol{Y}^{(0)}=\boldsymbol{E}_{\text{target}}+\boldsymbol{P}_{\text{target}} \tag{73} $$与 encoder 相比,decoder 也有六个解码器层,但其每个解码器层相比编码器层都多出一个用于注入 encoder 所提供的上下文表示的额外 attention 子层。解码器层由如下三个子层组成,按前馈顺序:
- Masked Multi-Head Self-Attention 子层,通过因果掩码确保自回归生成时当前位置只能访问到自身及其之前的位置,避免标签泄漏;
- Multi-Head Cross-Attention 子层,用于注入 encoder 的上下文表示,query 来自 decoder 当前隐状态(即 Masked Multi-Head Self-Attention 子层的输出);
- 逐位置独立作用的 FFN 子层。
若记第 $l$ 层 decoder 的输入为 $\boldsymbol{Y}^{(l-1)}$、encoder 的最终输出为 $\boldsymbol{X}^{(6)}$,$1\leqslant l\leqslant 6$,则解码器层的每一层计算的数学表示为
$$ \tilde{\boldsymbol{Y}}^{(l)}=\mathrm{LayerNorm}\big(\underbrace{\boldsymbol{Y}^{(l-1)}}_{\text{Residual}}+\mathrm{MaskedMultiHeadAttention}(\boldsymbol{Y}^{(l-1)},\boldsymbol{Y}^{(l-1)},\boldsymbol{Y}^{(l-1)})\big) \tag{74} $$$$ \hat{\boldsymbol{Y}}^{(l)}=\mathrm{LayerNorm}\big(\underbrace{\tilde{\boldsymbol{Y}}^{(l)}}_{\text{Residual}}+\mathrm{MultiHeadAttention}(\tilde{\boldsymbol{Y}}^{(l)},\boldsymbol{X}^{(6)},\boldsymbol{X}^{(6)})\big) \tag{75} $$$$ \boldsymbol{Y}^{(l)}=\mathrm{LayerNorm}\big(\underbrace{\hat{\boldsymbol{Y}}^{(l)}}_{\text{Residual}}+\mathrm{FFN}(\hat{\boldsymbol{Y}}^{(l)})\big) \tag{76} $$当最后一层解码器层输出 $\boldsymbol{Y}^{(6)}$ 后,模型再通过线性层与 Softmax 函数得到每一个位置的下一个 token 的预测概率分布,即
$$ \underbrace{\boldsymbol{Z}}_{\text{logits}}=\boldsymbol{Y}^{(6)}\boldsymbol{W}+\boldsymbol{b} \tag{77} $$$$ \boldsymbol{P}=\mathrm{Softmax}_{\text{over vocabulary}}(\boldsymbol{Z}) \tag{78} $$得到预测概率分布后,我们根据预测概率分布通过采样技术得到具体的 token。
许多 LLM 的 API 都支持 Temperature 超参数,实际上该参数只对基座模型计算得到的 logits 进行缩放,与基座模型内部的计算过程无关。记 Temperature 超参数为 $Temp$,则一种常见的支持 Temperature 参数的采样方式是
$$ \boldsymbol{P}_{Temp}=\mathrm{Softmax}_{\text{over vocabulary}}\bigg(\frac{\boldsymbol{Z}}{Temp}\bigg) \tag{79} $$通常 Temperature 被设定为非负数(取 0 时特殊考虑贪心策略),该值越大越容易得到小 logits 的 token。例如,当 Temperature 被设定为 0 时,采样时直接选取 logits 最大的 token,即 $\mathrm{token}_i={\arg\max}_{j}\boldsymbol{P}_{ij}$,于是模型的输出完全确定唯一、高度一致;反之,若 Temperature 较大,则会得到更多样多元、更不可控甚至上下文不连贯的输出。
根据目前为止的工程经验,对多数实践中的常见推荐 $Temp$ 取 $[0.5,0.9]$ 内的数,比如 $0.7$。
若源序列长度为 $n$、目标序列长度为 $m$、模型维度为 $d$、FFN 的中间层维度为 $d_{\text{ff}}$,则单个解码器层的计算复杂度可近似写为
$$ O(m^2d)+O(mnd)+O(mdd_{\text{ff}}) \tag{80} $$其中第一项来自 Masked Self-Attention,第二项来自 Cross-Attention,第三项来自 FFN。可见,相较于 encoder,decoder 每层多出了一项与源序列长度和目标序列长度同时相关的 Cross-Attention 代价。
不过,尽管模型在每个位置都可以给出下一个 token 的概率分布,但我们真正关心的是当前已生成序列(本轮自回归过程的输入)的下一个 token 的概率,即输出序列的最后一个位置所对应的预测分布 $P(y_t|y_1,y_2,\cdots,y_{t-1})$。通过采样得到 $y_t$ 后,我们把它插入到已生成序列并将更新后的已生成序列再次作为输入,然后重复该过程,直到某轮自回归过程计算出下一个 token 为终止标记 token $\langle EOS\rangle$。这就是 decoder 自回归生成的基本方式,通过这样一步步迭代,最终输出一个完整的序列。
自回归过程的概率模型为
$$ P(y_1,y_2,\cdots,y_T)=\prod^{T}_{t=1}P(y_t|y_1,y_2,\cdots,y_{t-1}) \tag{81} $$因此,尽管 encoder 与 decoder 内计算 attention 是并行的,但 decoder 生成结果时仍然是以自回归的方式逐个输出 token 的。
如上文所述,decoder 在推理阶段以自回归的方式逐个输出 token,因此若未采取任何优化措施,每个 token 的生成都是十分昂贵的。所幸,KV Cache 可以帮助我们避免大量重复计算,从而极大地降低计算量。
早在 2017 年的《Attention Is All You Need》中在首次提出 Transformer 时就已经蕴含了这一设计,只不过那时该机制还没有被系统化整理,也没有如今这个如雷贯耳的名字。
所谓 KV Cache,其实就是使用缓存存储自回归中先前时间步中已计算的 $\boldsymbol{K},\boldsymbol{V}$ 以避免重复计算。本质上 KV Cache 只是一个普通的缓存,但它在自回归中 attention 计算上太过于重要,以至于我们特别提出 KV Cache 这一术语。今天,KV Cache 已经成为了 LLM 推理能够顺利落地的核心优化措施。
现在我们分析为什么自回归时可以缓存 $\boldsymbol{K},\boldsymbol{V}$ 以降低计算量,同时不必缓存 $\boldsymbol{Q}$。
- 从 $(73),(74),(75),(31)$ 式可以看出,对于 decoder 的第 $l$ 层,考虑自回归过程的先后两次当前层的输入序列 $(y_1,y_2,\cdots,y_T)$ 与 $(y_1,y_2,\cdots,y_{T+1})$,不难知道两个序列的前 $T$ 个元素都是相同的(提示:第一数学归纳法易证);
- 因果掩码的加入,使得 attention 是单向的,即 $\forall i\lt T+1$,$\boldsymbol{\mathrm{attention}}_{i}$ 与 $y_{T+1}$ 无关;又由第一点可知,两个输入序列前 $T$ 个元素也是相同的,故两序列的前 $T$ 个 attention 的值也是恒定不变的。综上,我们只需要计算 $\boldsymbol{\mathrm{attention}}_{T+1}$,然后将 $\boldsymbol{\mathrm{attention}}_{T+1}$ 插入到上一轮自回归得到的 attention 序列 $\{\boldsymbol{\mathrm{attention}}_{i}\}^{T}_{i=1}$,这一技巧称为 incremental decoding;
- 根据 $(30)$ 式 $\boldsymbol{\mathrm{attention}}_{T+1}=\sum\limits^{T+1}_{i=1}a_{T+1,i}\boldsymbol{v}_i$、$a_{T+1,i}=\frac{\exp(\boldsymbol{S}_{T+1,i})}{\sum\limits^{T+1}_{j=1}\exp(\boldsymbol{S}_{T+1,j})}$ 与 $\boldsymbol{S}_{T+1,j}=\mathrm{score}(\boldsymbol{q}_{T+1},\boldsymbol{k}_j)$ 可以知道,$\boldsymbol{\mathrm{attention}}_{T+1}$ 的值仅与 $\boldsymbol{q}_{T+1},\{\boldsymbol{v}_i\}^{T+1}_{i=1},\{\boldsymbol{k}_i\}^{T+1}_{i=1}$ 有关,而与 $\{\boldsymbol{q}_i\}^{T}_{i=1}$ 无关,加之两个输入序列的前 $T$ 个元素是相同的,因此 $\{\boldsymbol{v}_i\}^{T}_{i=1},\{\boldsymbol{k}_i\}^{T}_{i=1}$ 也是固定的、可复用的,这就是为什么我们可以缓存 $\boldsymbol{K},\boldsymbol{V}$ 而不必缓存 $\boldsymbol{Q}$ 的根本原因。
在明确了为什么 KV Cache 需要且仅需要缓存 $\boldsymbol{K},\boldsymbol{V}$ 且没有必要缓存 $\boldsymbol{Q}$ 后,我们对 KV Cache 进行复杂度分析,以推导其「究竟用多少空间换了多少时间」。下文若未特别说明,均只讨论 decoder 自回归推理阶段中单层 Self-Attention 的主导项复杂度,并忽略线性投影、FFN 与常数项。
以《Attention Is All You Need》中提出的 Transformer 为例,如上文所述,在 Self-Attention 的场景下若输入序列长度为 $n$,则并行地计算一次 attention 的时间复杂度为 $O(n^2d)$。在自回归推理阶段,若未使用 KV Cache,则在生成第 $t$ 个 token 时需要对当前长度为 $t$ 的完整前缀重新计算一次 attention,故此时第 $t$ 步的时间复杂度为 $O(t^2d)$;将各步求和后,最终生成长度为 $T$ 的序列的总时间复杂度为 $\sum_{t=1}^{T}O(t^2d)=O(T^3d)$。
而若应用 KV Cache,计 decoder 共堆叠 $L$ 层,则在生成到第 $t$ 步时,为了存储每一层中 $t\times d$ 形状的 key 矩阵与 value 矩阵,我们需要付出 $O(Ltd)$ 的空间开销;当完整生成长度为 $T$ 的序列后,总空间复杂度来到 $O(LTd)$。但这或许是值得的,因为我们在第 $t$ 步只需要计算新位置 $\boldsymbol{\mathrm{attention}}_{t}$,该步时间复杂度为 $O(td)$——开销主要来自于 $\boldsymbol{q}_t\boldsymbol{K}$ 的计算;将各步求和后,最终总时间复杂度从 $O(T^3d)$ 降至 $\sum_{t=1}^{T}O(td)=O(T^2d)$。
KV Cache 仅在推理阶段有效。
我们通常将现代 Transformer LLM 推理的生成过程拆分为 prefill 与 decode 两个阶段,其中 prefill 是指模型首次读取整段输入 prompt 并建立 KV Cache 的阶段(即生成第一个 token 前的阶段),而 decode 阶段则是模型自回归生成新 token 的阶段。也就是说,KV Cache 通常被认为是属于 decoder 的结构(更准确地讲,属于 decoder self-attention),在 prefill 阶段根据输入 prompt 批量构建,并在随后的 decode 阶段 incremental decoding 继续增量扩展。
通常而言,prefill 阶段的总计算量会更大,因为此时尚未建立可复用的 KV Cache——毕竟建立 KV Cache 本身也是 prefill 阶段的工作内容之一,故 attention 计算相对于输入长度通常呈平方级别增长;而来到自回归 decode 阶段,由于 KV Cache 的存在,每生成一个新 token 时,attention 计算相对于当前上下文长度通常是线性级别的,计算成本相对更低。
有趣的是,尽管 prefill 阶段计算量更大,但 prefill 阶段往往能够让 GPU、TPU 等并行计算设备更充分地发挥性能,这是因为输入 prompt 是固定的、确定的,模型不必等待自回归过程输出新 token,因此同一层内不同 token 的 Q/K/V、attention 的计算以及 KV Cache 的构建都是可以并行进行的。
综上所述,在衡量现代 Transformer LLM 推理速度的时候,我们通常会分别考察 prefill 与 decode 两个阶段的耗时。
所谓的 TTFT(Time To First Token,首 token 响应延迟)是 LLM 供应商最看重的用户体验指标之一,该指标的值受到网络延迟、服务器负载、请求排队、tokenizer 开销等多方面的影响,而其中最耗时的环节往往正是 prefill 阶段——尤其是在 prompt 较长的场景下。
相应的,所谓的 TPOT(Time Per Output Token)则指后续 token 的生成平均耗时;TPS(Tokens Per Second)则是 TPOT 的近似倒数,表示平均每秒生成的 token 数。
这些性能指标可被归类为 throughput(吞吐量指标,包括 TPS)与 latency(延迟指标,包括 TTFT、TPOT)两大类。关于其他衡量用户体验的大模型性能指标,这里就不再展开了,它们不是本文的主要介绍内容。
Encoder & Decoder 的关系
今天,基于 Transformer 的主流 LLM 移除了 encoder 的设计,几乎都可以认为是 Decoder-only 的架构,比如 GPT、Claude、GLM、DeepSeek 与 Gemini(截止至 2026/3/30,其中 Gemini 在视觉与音频多模态存在 encoder 设计)。
是 encoder 不被需要了吗?至少在纯文本自回归生成的场景下,Decoder-only 往往被认为比 Full Encoder-Decoder 更高效,这或许是今天 Decoder-only 成为生成式 AI 主流设计的一种原因,不过我没有找到能支撑这个观点的权威文献。但不管怎样,文本生成的确是一类典型的长序列建模问题。
源序列与目标不一致时,即类似 $P(\boldsymbol{y}|\boldsymbol{x})$ 的「Seq2Seq」问题,或许依然适合 Full Encoder-Decoder?
2019 年 OpenAI 为发布 GPT-2 撰写的论文《Language Models are Unsupervised Multitask Learners》中指出,统一使用自回归语言建模目标 $P(y_1,y_2,\cdots,y_T)=\prod\limits^{T}_{t=1}P(y_t|y_{\lt t})$ 可以让模型在多种任务上均获得强泛化能力。Decoder-only 能在今天大行其道,至少说明这种统一的自回归建模方式在 LLM 时代有充分的实践价值。
但这并不意味着 encoder 是毫无用处的,
- Google 在 2025 年发布的生成式 LLM T5Gemma 便重新引入了 encoder,一个可能的目的是为了大幅缩减 decoder 的参数量,降低 KV Cache 的空间开销,从而支持侧端 AI 部署;
- 在生成式 AI 以外的场景,甚至出现了像 2024 年 ModernBERT 这样的 Encoder-only 模型——不过它并不是生成式 LLM,其职责是将文本「深度理解」后进行分类,在情感分析、代码检索等任务上有亮眼的能力。
在当下(截止至 2026/3/30),纯文本生成式 AI 普遍已将 encoder 排除在主架构之外,而多模态 AI 则通常具有 encoder,甚至为处理多种类型的输入(如图片、视频、音频、激光信号等)而具有多种 encoder。这有个很形象的直观:Decoder 越来越像「大脑」,而 encoder 越来越像「传感器」。
参考文献:
- Radford, Alec, Jeff Wu, Rewon Child, David Luan, Dario Amodei and Ilya Sutskever. “Language Models are Unsupervised Multitask Learners.” (2019).
最优化问题与反向传播算法
* 如果对经典 Transformer 的梯度推导不感兴趣或者有「数学公式恐惧症」,则可以略过本小节。
上文已经给出了经典 Transformer 在训练与推理时的前向结构,即 decoder 以右移后的目标序列作为输入,首先经由 $(73),(74),(75)$ 三式得到最后一层解码器层所输出的 $\boldsymbol{Y}^{(6)}$,再经由 $(76),(77)$ 二式得到各位置上的 logits 与相应的预测概率分布。现在我们重点在梯度的数学形式上分析一下经典 Transformer 中的最优化问题及 BP 算法。
条件语言建模目标对于源序列 $\boldsymbol{x}=(x_1,x_2,\cdots,x_n)$ 与目标序列 $\boldsymbol{y}=(y_1,y_2,\cdots,y_m)$,经典 Encoder-Decoder Transformer 在训练时的优化目标是典型的条件自回归语言建模目标
$$ P(y_1,y_2,\cdots,y_m|\boldsymbol{x})=\prod_{t=1}^{m}P(y_t|y_1,y_2,\cdots,y_{t-1},\boldsymbol{x}) \tag{82} $$这与上文所给出的 decoder 自回归概率分解 $(80)$ 式在形式上是完全一致的,只不过明确了对源序列 $\boldsymbol{x}$ 的条件依赖。对于 Text-to-Text 的条件语言建模任务,本质上是「输入 token → 预测输出 token」的监督学习任务,即概率分布预测任务,因此顶层的损失函数一般考虑交叉熵。
在 Teacher Forcing 下,decoder 的输入是右移后的目标前缀,而监督信号则是不右移的真实目标序列本身。记词表大小为 $V$,并记
- $\boldsymbol{Y}'\in\mathbb{R}^{m\times V}$ 为标签矩阵,其第 $t$ 行为真实目标 token $y_t$ 对应 one-hot 向量的转置;
- $\boldsymbol{P}\in\mathbb{R}^{m\times V}$ 为 $(77)$ 式得到的预测概率矩阵,其第 $t$ 行给出位置 $t$ 上下一个 token 的预测分布。
若暂不考虑 padding 掩码,则经典 Transformer 在单个样本上的交叉熵损失为
$$ \mathcal{L}_{\text{CE}}=-\sum_{t=1}^{m}\sum_{c=1}^{V}Y'_{t,c}\log P_{t,c} \tag{83} $$由于在批次训练中不同序列的长度可能不同,在实现中常常使用 padding 标志 $\langle PAD\rangle$ 将短序列尾填充至与长序列相同的长度。
显然,在模型的训练中应当忽视没有语义的 padding 标志,因此实际的损失函数通常还会在上式上额外再乘以 loss 掩码,其作用是标记有效 token 位置,从而使最后计算损失时仅对有效 token 求和或求平均。不过,这并不会改变下文将要推导的梯度形式,只会将被掩码所作用的对应位置梯度置零。
输出层梯度由于 $(77)$ 式仍是 “线性层 + Softmax + 交叉熵” 的组合,因此其局部梯度与上在 RNN 章节的 $(15),(16)$ 式推导是完全一致的,于是有
$$ \frac{\partial\mathcal{L}_{\text{CE}}}{\partial\boldsymbol{Z}}=\boldsymbol{P}-\boldsymbol{Y}' \tag{84} $$再由 $(76)$ 式 $\boldsymbol{Z}=\boldsymbol{Y}^{(6)}\boldsymbol{W}+\boldsymbol{b}$,求导立即得
$$ \boxed{\frac{\partial\mathcal{L}_{\text{CE}}}{\partial\boldsymbol{W}}=(\boldsymbol{Y}^{(6)})^T(\boldsymbol{P}-\boldsymbol{Y}')},\qquad \boxed{\frac{\partial\mathcal{L}_{\text{CE}}}{\partial\boldsymbol{b}}=\boldsymbol{1}_m^T(\boldsymbol{P}-\boldsymbol{Y}')},\qquad \boxed{\frac{\partial\mathcal{L}_{\text{CE}}}{\partial\boldsymbol{Y}^{(6)}}=(\boldsymbol{P}-\boldsymbol{Y}')\boldsymbol{W}^T} \tag{85} $$其中 $\boldsymbol{1}_m\in\mathbb{R}^{m\times1}$。若实际训练中对有效 token 数作平均,则只需在上式右侧整体再除以有效 token 数。
内部梯度现在我们从输出层逐步向底层分析经典 Transformer 内部的梯度流动。
由 $(84)$ 式,最后一层解码器层输出的上游梯度为
$$ \bar{\boldsymbol{Y}}^{(6)}\triangleq\frac{\partial\mathcal{L}_{\text{CE}}}{\partial\boldsymbol{Y}^{(6)}}=(\boldsymbol{P}-\boldsymbol{Y}')\boldsymbol{W}^T \tag{86} $$这里及下文统一用上划线表示对相应变量的梯度。又由于各子层外都包裹了残差连接与 LayerNorm,为简洁起见,对于 $\boldsymbol{R}=\mathrm{LayerNorm}(\boldsymbol{U})$,记
$$ \mathcal{D}_{\mathrm{LN}}(\boldsymbol{U},\bar{\boldsymbol{R}}) \triangleq \mathrm{VJP}_{\mathrm{LayerNorm},\boldsymbol{U}}(\boldsymbol{U};\bar{\boldsymbol{R}}) \tag{87} $$这里 $\mathrm{VJP}$ 表示 LayerNorm 关于输入 $\boldsymbol{U}$ 的 Jacobian 与上游梯度 $\bar{\boldsymbol{R}}$ 的缩并结果,即 LayerNorm 对上游梯度的回传结果;若 LayerNorm 含可学习参数,则可以通过按逐元素仿射变换得到其参数梯度。
VJP 全称 Vector-Jacobian Product,该算子的具体推导与形式请查阅现代自动微分理论的相关文献。LayerNorm 的前向计算包含均值中心化和方差归一化,这导致它的 Jacobian 矩阵非常复杂,所以 VJP 的形式也异常冗长,简洁起见,本文不对 VJP 做推导。
对任意一个 Multi-Head Attention 模块,记
$$ \boldsymbol{H}=\mathrm{Concat}(\mathrm{head}_1,\mathrm{head}_2,\cdots,\mathrm{head}_h),\qquad \mathrm{MHA}(\boldsymbol{X}_Q,\boldsymbol{X}_K,\boldsymbol{X}_V)=\boldsymbol{H}\boldsymbol{W}_O \tag{88} $$若其输出的上游梯度为 $\bar{\boldsymbol{M}}$,则由输出投影得到
$$ \frac{\partial\mathcal{L}}{\partial\boldsymbol{W}_O}=\boldsymbol{H}^T\bar{\boldsymbol{M}},\qquad \bar{\boldsymbol{H}}=\bar{\boldsymbol{M}}\boldsymbol{W}_O^T \tag{89} $$接着,再将 $\bar{\boldsymbol{H}}$ 按特征维切分到各个 head,并对每个 head 引用上文 attention 章节推导出的 $(37),(42),(44),(46),(47)$ 式,便得到其对 $\boldsymbol{X}_Q,\boldsymbol{X}_K,\boldsymbol{X}_V$ 以及 $\boldsymbol{W}_Q^{(r)},\boldsymbol{W}_K^{(r)},\boldsymbol{W}_V^{(r)}$ 的梯度,最后将各 head 对同一输入的梯度相加即可。若带因果掩码或 padding 掩码,则只需将被掩码所作用的对应 score 位置对应的 $\frac{\partial\mathcal{L}}{\partial S_{ij}}$ 置零。
然后,梯度按 $l=6,5,\cdots,1$ 的顺序在 decoder 内反向传播。对于第 $l$ 层 decoder 的 FFN 子层,记
$$ \boldsymbol{A}_f^{(l)}=\hat{\boldsymbol{Y}}^{(l)}\boldsymbol{W}_1^{(l)}+\boldsymbol{b}_1^{(l)},\qquad \boldsymbol{F}^{(l)}=\varphi(\boldsymbol{A}_f^{(l)})\boldsymbol{W}_2^{(l)}+\boldsymbol{b}_2^{(l)},\qquad \boldsymbol{U}_f^{(l)}=\hat{\boldsymbol{Y}}^{(l)}+\boldsymbol{F}^{(l)} \tag{90} $$则由 $(75)$ 式有
$$ \bar{\boldsymbol{U}}_f^{(l)}=\mathcal{D}_{\mathrm{LN}}(\boldsymbol{U}_f^{(l)},\bar{\boldsymbol{Y}}^{(l)}),\qquad \boldsymbol{\Delta}_f^{(l)}\triangleq\Big(\bar{\boldsymbol{U}}_f^{(l)}(\boldsymbol{W}_2^{(l)})^T\Big)\odot\varphi'(\boldsymbol{A}_f^{(l)}) \tag{91} $$于是
$$ \frac{\partial\mathcal{L}}{\partial\boldsymbol{W}_2^{(l)}}=\varphi(\boldsymbol{A}_f^{(l)})^T\bar{\boldsymbol{U}}_f^{(l)},\quad \frac{\partial\mathcal{L}}{\partial\boldsymbol{b}_2^{(l)}}=\boldsymbol{1}_m^T\bar{\boldsymbol{U}}_f^{(l)},\quad \frac{\partial\mathcal{L}}{\partial\boldsymbol{W}_1^{(l)}}=(\hat{\boldsymbol{Y}}^{(l)})^T\boldsymbol{\Delta}_f^{(l)},\quad \frac{\partial\mathcal{L}}{\partial\boldsymbol{b}_1^{(l)}}=\boldsymbol{1}_m^T\boldsymbol{\Delta}_f^{(l)} \tag{92} $$考虑残差链接,将残差支路与 FFN 支路的梯度相加,从而有
$$ \bar{\hat{\boldsymbol{Y}}}^{(l)}=\bar{\boldsymbol{U}}_f^{(l)}+\boldsymbol{\Delta}_f^{(l)}(\boldsymbol{W}_1^{(l)})^T \tag{93} $$对于 Cross-Attention 子层,记
$$ \boldsymbol{U}_c^{(l)}=\tilde{\boldsymbol{Y}}^{(l)}+\mathrm{MultiHeadAttention}(\tilde{\boldsymbol{Y}}^{(l)},\boldsymbol{X}^{(6)},\boldsymbol{X}^{(6)}) \tag{94} $$由 $(74)$ 式与 $(87)$ 式,进一步可得
$$ \bar{\boldsymbol{U}}_c^{(l)}=\mathcal{D}_{\mathrm{LN}}(\boldsymbol{U}_c^{(l)},\bar{\hat{\boldsymbol{Y}}}^{(l)}),\qquad \bar{\tilde{\boldsymbol{Y}}}^{(l)}=\bar{\boldsymbol{U}}_c^{(l)}+\bar{\boldsymbol{X}}_{Q}^{(l,\mathrm{ca})} \tag{95} $$其中 $\bar{\boldsymbol{X}}_{Q}^{(l,\mathrm{ca})},\bar{\boldsymbol{X}}_{K}^{(l,\mathrm{ca})},\bar{\boldsymbol{X}}_{V}^{(l,\mathrm{ca})}$ 分别表示该 Cross-Attention 模块对 query、key、value 输入的梯度。由于 $\boldsymbol{X}^{(6)}$ 同时充当 key 与 value,因此所有 decoder 层对 encoder 输出的梯度应累加为
$$ \bar{\boldsymbol{X}}^{(6)}=\sum_{l=1}^{6}\Big(\bar{\boldsymbol{X}}_{K}^{(l,\mathrm{ca})}+\bar{\boldsymbol{X}}_{V}^{(l,\mathrm{ca})}\Big) \tag{96} $$对于 Masked Self-Attention 子层,记
$$ \boldsymbol{U}_s^{(l)}=\boldsymbol{Y}^{(l-1)}+\mathrm{MaskedMultiHeadAttention}(\boldsymbol{Y}^{(l-1)},\boldsymbol{Y}^{(l-1)},\boldsymbol{Y}^{(l-1)}) \tag{97} $$则由 $(73)$ 式与 $(87)$ 式,有
$$ \bar{\boldsymbol{U}}_s^{(l)}=\mathcal{D}_{\mathrm{LN}}(\boldsymbol{U}_s^{(l)},\bar{\tilde{\boldsymbol{Y}}}^{(l)}),\qquad \bar{\boldsymbol{Y}}^{(l-1)}=\bar{\boldsymbol{U}}_s^{(l)}+\bar{\boldsymbol{X}}_{Q}^{(l,\mathrm{sa})}+\bar{\boldsymbol{X}}_{K}^{(l,\mathrm{sa})}+\bar{\boldsymbol{X}}_{V}^{(l,\mathrm{sa})} \tag{98} $$其中,$(98)$ 式之所以要将三条梯度路径与残差路径全部相加以计算 $\bar{\boldsymbol{Y}}^{(l-1)}$,是因为在 Self-Attention 中 $\boldsymbol{Y}^{(l-1)}$ 同时作为 query、key 与 value 输入。
对于 encoder,反向传播是完全同理的:FFN 子层的梯度依然按 $(93)$ 式计算,Self-Attention 子层的梯度依然按 $(98)$ 式计算,只需将 $\boldsymbol{Y}$ 全部替换为 $\boldsymbol{X}$ 并不再考虑因果掩码,在编码器层自 $l=6$ 递推至 $l=1$,直至回到模型的输入端。
这里直接给出结果。此处 $\boldsymbol{E}$ 与 $\boldsymbol{E}_{\text{target}}$ 均表示经 embedding lookup 后按行堆叠得到的序列表示矩阵,而非词表级的 embedding 参数表;同时,为避免与预测概率矩阵 $\boldsymbol{P}$ 混淆,此处将 $(69)$ 式中的源侧位置编码临时记为 $\boldsymbol{P}_{\text{src}}$。由 $(69),(73)$ 式,有
$$ \frac{\partial\mathcal{L}}{\partial\boldsymbol{E}}=\frac{\partial\mathcal{L}}{\partial\boldsymbol{X}^{(0)}},\qquad \frac{\partial\mathcal{L}}{\partial\boldsymbol{P}_{\text{src}}}=\frac{\partial\mathcal{L}}{\partial\boldsymbol{X}^{(0)}},\qquad \frac{\partial\mathcal{L}}{\partial\boldsymbol{E}_{\text{target}}}=\frac{\partial\mathcal{L}}{\partial\boldsymbol{Y}^{(0)}} \tag{99} $$若进一步回传至词表级 embedding 参数,则需要将同一 token 在序列中各位置上的梯度离散累加;例如对源序列中第 $v$ 个词对应的 embedding 向量 $\boldsymbol{e}_v$,有
$$ \frac{\partial\mathcal{L}}{\partial\boldsymbol{e}_v} =\sum_{t:x_t=v}\frac{\partial\mathcal{L}}{\partial\boldsymbol{E}_t} =\sum_{t:x_t=v}\frac{\partial\mathcal{L}}{\partial\boldsymbol{X}^{(0)}_t} \tag{100} $$这与 decoder 在输入侧的梯度是完全类似的。若目标侧位置编码也是可学习参数,则同样有 $\frac{\partial\mathcal{L}}{\partial\boldsymbol{P}_{\text{target}}}=\frac{\partial\mathcal{L}}{\partial\boldsymbol{Y}^{(0)}}$。
相较于 BPTT,RNN 的梯度需要沿隐状态链 $\boldsymbol{h}_1\to\boldsymbol{h}_2\to\cdots\to\boldsymbol{h}_T$ 在时间维度上递推,这决定了 BPTT 必然存在无法根本优化的递归结构;而 Transformer 在 Teacher Forcing 下却并不存在这样的时间递归链,所有位置的损失可以一次性并行计算,梯度通过 attention 所建立的全连接依赖图在层间与位置间传播,并不需要通过时间递推回传。
这也更深刻地解释了上文在分析 attention 时强调的「任意两个 token 间都至少存在一条长度为 1 的梯度路径」:在训练经典 Transformer 时,长程依赖的优化正是通过这样的全连接梯度路径完成的,而非像 RNN 那样被迫经过一长串递归状态。