引言
在第一篇文章 MLP 与 BP 算法的数学原理 中,我们简单地推导并实践了神经网络的基础——BP 算法。
在第二篇文章 经典注意力与经典 Transformer 的数学原理 中,我们梳理了从 RNN & BPTT、Seq2Seq、注意力机制再到经典 Transformer 的时间线,并详细地在其底层数学原理的层次上进行了推导与分析。
本文将在前两篇文章的基础上,借助多篇或经典或前沿的文献梳理 MoE(Mixture of Experts,混合专家模型)的基础理论。如果说,BP 算法使得我们能够构造可训练的前馈神经网络,注意力与 Transformer 使得我们拥有了一种强大的序列模型范式,那么 Sparse MoE 就是 Transformer 从「小模型」真正迈向「大模型」的关键一招。
Dense Scaling 的瓶颈
在大模型领域,有一条被称为 Scaling Law(缩放定律,参见 2020 年 Kaplan 等人的研究 Scaling Laws for Neural Language Models)的经验定律:模型性能(例如训练损失)随投入资源(例如参数量)的增加而平滑提升,且遵循幂律关系。这是在众多大型实验室的实践中得出的经验总结。
$$ Loss(C) \approx \left( \frac{C_{\text{min}}}{C} \right)^{\alpha} \tag{1} $$其中 $C$ 表示训练计算量(FLOPs),$\alpha$ 为缩放指数(通常取值 $0.05\sim0.1$),$C_{\text{min}}$ 则为一个常数。Scaling Law 表明,要提升模型的性能,一个可行的方案就是提高模型的参数规模。但同时 Scaling Law 也为我们估计了一个残酷的代价:要使损失降低 $n$ 倍,需要付出 $n^{\frac1{\alpha}}$ 倍的计算开销。即,参数规模的边际收益是递减的,但我们又不得不面对这个现实。
这为我们带来一个难题:为了更佳的性能,我们可以选择提升参数规模。可是,当参数规模过大时,模型的训练成本很可能大到我们无法接受。
我们称在前向传播时每一层的所有参数都会被激活并参与计算的模型为稠密模型(Dense Model),反之则称为稀疏激活模型(Sparsely-Activated Model)。在 MLP 与 BP 算法的数学原理 与 经典注意力与经典 Transformer 的数学原理 中介绍并导出的所有模型均属于此类。对于稠密模型而言,Dense Scaling 是不可持续的。
我们希望有一种方案,使得模型拥有可观的总参数规模同时,在训练阶段却只计算其中一小部分的参数,从而大大降低训练成本。MoE 在深度学习中的应用,正是为了解决这个问题。
参考文献:
- Kaplan, Jared, Sam McCandlish, Thomas Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeff Wu and Dario Amodei. “Scaling Laws for Neural Language Models.” ArXiv abs/2001.08361 (2020): n. pag.
早期 MoE
1991. Mixture Likelihood & Experts
MoE 最早可追溯到 1991 年 Robert A. Jacobs 等人提出的 Adaptive Mixtures of Local Experts。为了使 MLP 能够执行多种不同子任务,文献将模型分为了 Local Expert Networks 与 Gating Network 两部分。其中,每个 Local Expert Network 都较小且简单——在原论文中仅仅是小型 FFN,负责处理元音识别任务;Gating Network 的作用则类似调度器,不直接预测任务目标,而是经 Softmax 归一化后输出各 Local Expert Network 对当前输入 $\boldsymbol{x}$ 的一个概率分布,该概率分布可被视为各 Local Expert Network 对当前输入的条件混合系数。最终的输出在训练时基于混合似然,在推理时则通过该概率分布对各 Local Expert Network 的输出取加权和得到。
该论文的一个重要创新点是设计了新的损失函数。文献指出,如果使用传统的 MSE 作为损失,系统将变得强耦合,因为每个 Local Expert Network 都试图在误差反向传播时弥补其他 Local Expert Network 的残差,于是系统便无法体现出「分工」的特征,所有的 Local Expert Network 都在学习相似的宽泛特征。为了解决这一问题,论文将对数似然作为损失。假设 $\boldsymbol{d}$ 的生成是根据 Gating Network 输出的概率分布按概率选中的某个 Local Expert Network 所输出的预测值并以该预测值为均值构造的正态分布的采样,即 $\boldsymbol{d}$ 服从关于 $\boldsymbol{x}$ 的条件混合高斯分布(GMM,Gaussian Mixture Model),见下式
$$ p(\boldsymbol{d}|\boldsymbol{x})=\sum_ip_i(\boldsymbol{x})\mathcal{N}(\boldsymbol{d};\boldsymbol{y}_i,\sigma^2\boldsymbol{I}) \tag{2} $$记 $\boldsymbol{y}_i$ 为第 $i$ 个 Local Expert Network 的输出值,则损失为
$$ \mathcal{L}=-\ln\sum_ip_{i}\exp\left(-\frac1{2\sigma^2}\Vert\boldsymbol{d}-\boldsymbol{y}_i\Vert^2\right)+C \tag{3} $$在该损失函数设计下,如果在训练早期某个 Local Expert Network 的预测比其他 Local Expert Network 的预测更准确,即使仅略准确一点,其最终受到的相对梯度权重($\frac{p_i\exp(-\frac1{2\sigma^2}\Vert\boldsymbol{d}-\boldsymbol{y}_i\Vert^2)}{\sum\limits_{j}p_j\exp(-\frac1{2\sigma^2}\Vert\boldsymbol{d}-\boldsymbol{y}_j\Vert^2)}$)也将被显著放大,该机制被称为 Soft Competition。这里直接给出梯度结果,记 $g_i$ 为 Gating Network 输出的第 $i$ 个logit,有
$$ \left\{\begin{aligned} &\frac{\partial\mathcal{L}}{\partial\boldsymbol{y}_i}=-\frac{p_i\exp(-\frac1{2\sigma^2}\Vert\boldsymbol{d}-\boldsymbol{y}_i\Vert^2)}{\sum\limits_{j}p_j\exp(-\frac1{2\sigma^2}\Vert\boldsymbol{d}-\boldsymbol{y}_j\Vert^2)}(\boldsymbol{d}-\boldsymbol{y}_i)\\ &\\ &\frac{\partial\mathcal{L}}{\partial g_i}=p_i-\frac{p_i\exp(-\frac1{2\sigma^2}\Vert\boldsymbol{d}-\boldsymbol{y}_i\Vert^2)}{\sum\limits_{j}p_j\exp(-\frac1{2\sigma^2}\Vert\boldsymbol{d}-\boldsymbol{y}_j\Vert^2)} \end{aligned}\right. \tag{4} $$传统的 MLP 中,各神经元体现为协作的关系,所有参数共同拟合同一个目标。原论文的一个关键改进点,就是通过混合似然损失引入专家间的竞争,从而诱导不同的专家学习不同的模式。
参考文献:
- R. A. Jacobs, M. I. Jordan, S. J. Nowlan and G. E. Hinton, “Adaptive Mixtures of Local Experts,” in Neural Computation, vol. 3, no. 1, pp. 79-87, March 1991, doi: 10.1162/neco.1991.3.1.79.
1991~2017 早期 MoE 实践简述
在 1991 年后、2017 年之前,有若干研究对 MoE 进行了实践与改进。这里选取其中几份有重要意义的文献进行简述。
- 1993 年 Hierarchical mixtures of experts and the EM algorithm 将 MoE 拓展为树状分层结构并引入 EM 算法训练网络,同时证明了 MoE 可以作为非线性回归和分类的通用近似器;
- 2002 年 A Parallel Mixture of SVMs for Very Large Scale Problems 将 SVM 作为专家,利用 MoE 的分治策略解决了彼时稠密 SVM 所无法处理的百万级样本量,展示了 MoE 在大规模参数量与数据集上的巨大潜力;
- 2013 年 Learning Factored Representations in a Deep Mixture of Experts 将 MoE 模块化为深度神经网络中的层,从而允许 MoE 像 CNN 中的卷积层类似堆叠。
这些研究对 MoE 的发展有重要意义,但限于时代因素,与深度学习的关联不大,因此这里不做展开。
参考文献:
- M. I. Jordan and R. A. Jacobs, “Hierarchical mixtures of experts and the EM algorithm,” Proceedings of 1993 International Conference on Neural Networks (IJCNN-93-Nagoya, Japan), Nagoya, Japan, 1993, pp. 1339-1344 vol.2, doi: 10.1109/IJCNN.1993.716791.
- R. Collobert, S. Bengio and Y. Bengio, “A Parallel Mixture of SVMs for Very Large Scale Problems,” in Advances in Neural Information Processing Systems 14: Proceedings of the 2001 Conference, T. G. Dietterich, S. Becker and Z. Ghahramani, Eds. Cambridge, MA, USA: The MIT Press, 2002, pp. 633-640, doi: 10.7551/mitpress/1120.003.0086.
- Eigen, David, Marc’Aurelio Ranzato and Ilya Sutskever. “Learning Factored Representations in a Deep Mixture of Experts.” CoRR abs/1312.4314 (2013): n. pag.
Dense MoE (MMoE & PLE)
* 如果读者只对大模型中的 MoE 技术发展路线感兴趣,则可以略过本章节。
本文主要聚焦于被广泛应用在大模型中的 MoE 技术,即 Sparse MoE。但 Dense MoE 在大模型之外的领域,如推荐系统,也有着极其广泛的使用。就技术上讲,二者代表了 MoE 的不同发展路线。因此,这里单独用一个章节通过 MMoE 与 PLE 介绍 Dense MoE。
再次强调,本文主题为 Sparse MoE,因此不会对 Dense MoE 做过多详细的解释。这不代表 Dense MoE 不重要,只是限于本文主旨,将 Dense MoE 压缩为一个单独的章节。
Dense MoE 与 Sparse MoE 是两种不同的 MoE 发展路线。后文将要重点研究的 Sparse MoE 主要聚焦于解决大模型参数量过大从而致使全量参数激活后计算困难的问题,但在进入到 Sparse MoE 的讨论以前,有必要简单介绍 Dense MoE 的发展路线。在多任务学习(Multi-Task Learning, MTL)与推荐系统领域,以 MMoE 与 PLE 为代表的 Dense MoE 是两个经典的里程碑式架构。
实际上,推荐系统正是典型的多任务学习,因为推荐算法通常需要同时优化多个目标。《Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts》中给出了这样一个例子:在系统向用户推荐电影时,往往并不仅希望用户购买并观看电影,而也希望用户在观看后能够喜欢这部电影,从而将电影推荐给亲友。再比如,短视频团队希望同时将播放率、点击率、分享率与评论率作为评价指标以优化推荐算法。
1993 年,Caruana 在《Multitask Learning: A Knowledge-Based Source of Inductive Bias》中描述了一种(在今天看来)传统的多任务学习架构,该架构的最大特点是底层表示共享,各任务仅在顶层交叉。这类共享底层表示的架构在后来被称为共享底座(Shared-Bottom 或 Hard Sharing)。记输入为 $\boldsymbol{x}$,则 $\boldsymbol{x}$ 经映射 $f_{\text{shared}}$ 得到底层表示 $\boldsymbol{h}$,第 $t$ 个任务的输出为 $\boldsymbol{y}^t=f_t(\boldsymbol{h})$。这在架构设计上并不复杂,Caruana 真正的贡献是在这篇文献里系统性地提出了「inductive bias from data itself」,即任务可以作为彼此的归纳偏置来源。
当数据不足或任务困难时,单任务的 MLP 很容易过拟合。在 1993 年以前,为了使模型具备更强的泛化能力,研究者常利用自身的先验知识人为地进行归纳偏置,例如为损失添加某种正则化约束或进行特征工程。Caruana 则 1993 年的这篇论文中明确指出,在多任务学习中,其他任务能够动态地作为彼此的归纳偏置来源,故不必人为地手工设计偏置。
然而,共享底座的设计存在一系列问题:
- 在任务之间差异较大、相关性较低时,不同任务对共享参数的梯度更新方向将发生冲突,导致优化困难;
- 训练中损失的方差较大,意味着损失曲面上存在大量较差的局部最小值,训练结果高度依赖初始化;
- 存在任务间的优化冲突,对某一任务的优化改进可能导致其他任务性能下降,即负迁移现象。
针对上述问题,Jiaqi Ma 于 2018 年在 Google 实习期间提出了 MMoE(Multi-gate Mixture-of-Experts),其关键改进是将共享底座网络 $f_{\text{shared}}$ 替换为 MoE 层,并且为每个任务均设置一个独立的门控网络 $g_k$。这样一来,第 $k$ 个任务的输出为
$$ \boldsymbol{y}^k=f_k(\boldsymbol{h}^k) $$其中 $\boldsymbol{h}^k$ 为 MoE 层的输出,有
$$ \boldsymbol{h}^k=\sum_{i=1}^{n}g_k(\boldsymbol{x})_i\, f_{\text{expert}_i}(\boldsymbol{x}) $$$$ g_k(\boldsymbol{x})=\operatorname{softmax}(\boldsymbol{W}_{gk}\,\boldsymbol{x}) $$此处 $\boldsymbol{W}_{gk}\in\mathbb{R}^{n\times d}$ 是可训练的参数矩阵,$n$ 为专家数量、$d$ 为特征维度。与后文 Sparse MoE 最大的不同是,每个任务上的最终输出会以不同的权重利用上所有专家的输出。
本质上,MMoE 是任务颗粒度上的 MoE 路由,使得不同任务能够在同一专家集合中选择不同的子空间表示。当任务间的相关性较弱时,门控网络倾向于激活不同专家,从而实现共享参数空间内的软解耦,显著缓解了任务间的优化冲突问题。与此同时,相较于 Cross-Stitch 或 Tensor-Factorization 等方法,MMoE 的额外计算开销仅来自轻量级的路由网络,故在取得良好效果的同时并未带来过多计算量。
尽管 MMoE 缓解了任务间的优化冲突问题,但由于 MMoE 架构中专家仍然是完全共享的,因此在任务相关性复杂或存在层级结构时仍可能出现表示耦合不足的问题,即所谓的跷跷板现象:某个任务性能的提升往往以损害其他任务性能为代价。这意味着门控网络无法完全隔离冲突信息。
为解决这一问题,2020 年,腾讯广告推荐系统团队提出了 PLE(Progressive Layered Extraction)架构。在该架构下,专家们被划分为共享专家与任务特化专家。对于负责某个任务的门控网络,该网络仅在当前层的共享专家与本任务特化专家的集合内进行加权组合,而不与其他任务的特化专家直接发生混合。这一结构被称为定制化门控控制(Customized Gate Control, CGC)。文献指出,通过将 CGC 结构纵向堆叠,能够将浅层抽取的复合特征传递至深层,实现更深度的特征渐进式提取。
PLE 的核心思想是:在结构上显式区分共享与任务特化表征,并通过逐层堆叠的 CGC 结构实现从浅层共享到深层特化的渐进式特征抽取,从而在更强表达能力的同时缓解多任务间的表示干扰。相较于 MMoE 的单层共享专家路由机制,PLE 通过引入显式的专家分组与层级化结构,将「软选择共享空间」扩展为「逐层特征分离过程」。
参考文献:
- Ma, Jiaqi, Zhe Zhao, Xinyang Yi, Jilin Chen, Lichan Hong and Ed H. Chi. “Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts.” Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (KDD ’18) (2018).
- Caruana, Rich. “Multitask Learning: A Knowledge-Based Source of Inductive Bias.” International Conference on Machine Learning (1993).
- Tang, Hongyan, Junning Liu, Ming Zhao and Xudong Gong. “Progressive Layered Extraction (PLE): A Novel Multi-Task Learning (MTL) Model for Personalized Recommendations.” Proceedings of the 14th ACM Conference on Recommender Systems (RecSys ’20) (2020).
2017. Sparsely-Gated MoE
从此处开始,本文将正式进入 Sparse MoE 的讨论——这也是目前大模型 MoE 所采用的主流方案。
2017 年,Google Brain 团队的 Noam Shazeer 等人在 Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer 中提出了稀疏门控(Sparsely-Gated MoE)。
这是 MoE 被应用在大模型之前夕的关键性进展。如果说 1991 年 Robert A. Jacobs 等人最早提出了(稠密的)MoE 架构,那么 2017 年 Google Brain 提出的稀疏门控技术则将 MoE 在参数规模与单 token 激活计算量之间实现了近似解耦,为工业领域超大参数规模大模型的落地彻底铺平了道路。
截止至 2026 年 5 月,部分市面上主流的 LLM 使用 MoE 的情况如下表:
| 模型系列 | 最先进公开版本 截止至 2026 年 5 月 | 是否使用稀疏门控 MoE | 备注 |
|---|---|---|---|
| ChatGPT OpenAI | GPT-5.5 (Thinking / Pro) | 推测是 | OpenAI 对近期模型的具体技术细节高度保密,但业界普遍认为自 GPT-4 时代起其已全面转向稀疏 MoE 或类似的高级稀疏架构,目前 GPT-5 系列大概率延续并深化了这一技术路线。 |
| Claude Anthropic | Claude 4.7 (Opus) | 推测是 | Anthropic 同样未公开其旗舰模型的具体结构,但面对超大规模推理与长期计算成本优化需求,其高端模型普遍被认为构建于 MoE 或类似的稀疏架构之上。 |
| Gemini | Gemini 3.1 (Pro / Ultra) | 是 | Gemini 系列在早期(如 Gemini 1.0)仍以稠密模型为主;自 Gemini 1.5 起,Google 已正式公开引入稀疏 MoE 架构,并延续至后续 Gemini 3.x 系列。 |
| DeepSeek 深度求索 | DeepSeek-V4 Pro | 是 | 稀疏门控 MoE 的代表性路线之一。DeepSeek 长期围绕细粒度专家划分、通信优化与无辅助损失负载均衡等方向持续演进,其 DeepSeekMoE 架构在开源社区与工业界均产生了巨大影响。 |
可见,稀疏门控 MoE 已经是事实上的行业标准。对于超大参数规模的主流大模型,无一例外均应用了稀疏 MoE 技术。
在原论文中,MoE 作为模型单独的一个层出现,即 Sparsely-Gated MoE Layer,简称 MoE 层。MoE 层可被划分为门控网络(Gating Network)与专家网络(Expert Network,简称专家 Expert)两个组件。原论文将稀疏门控 MoE 应用在机器翻译任务上,使用 LSTM 作为专家。
原论文指出,MoE 在每个位置上被调用一次、都有可能选择不同的专家组合,并且不同的专家倾向于根据句法和语义而变得高度专业化。
「不同的专家倾向于根据句法和语义而变得高度专业化」,这和多头注意力在机器翻译乃至通用 NLP 上的行为是相似的。
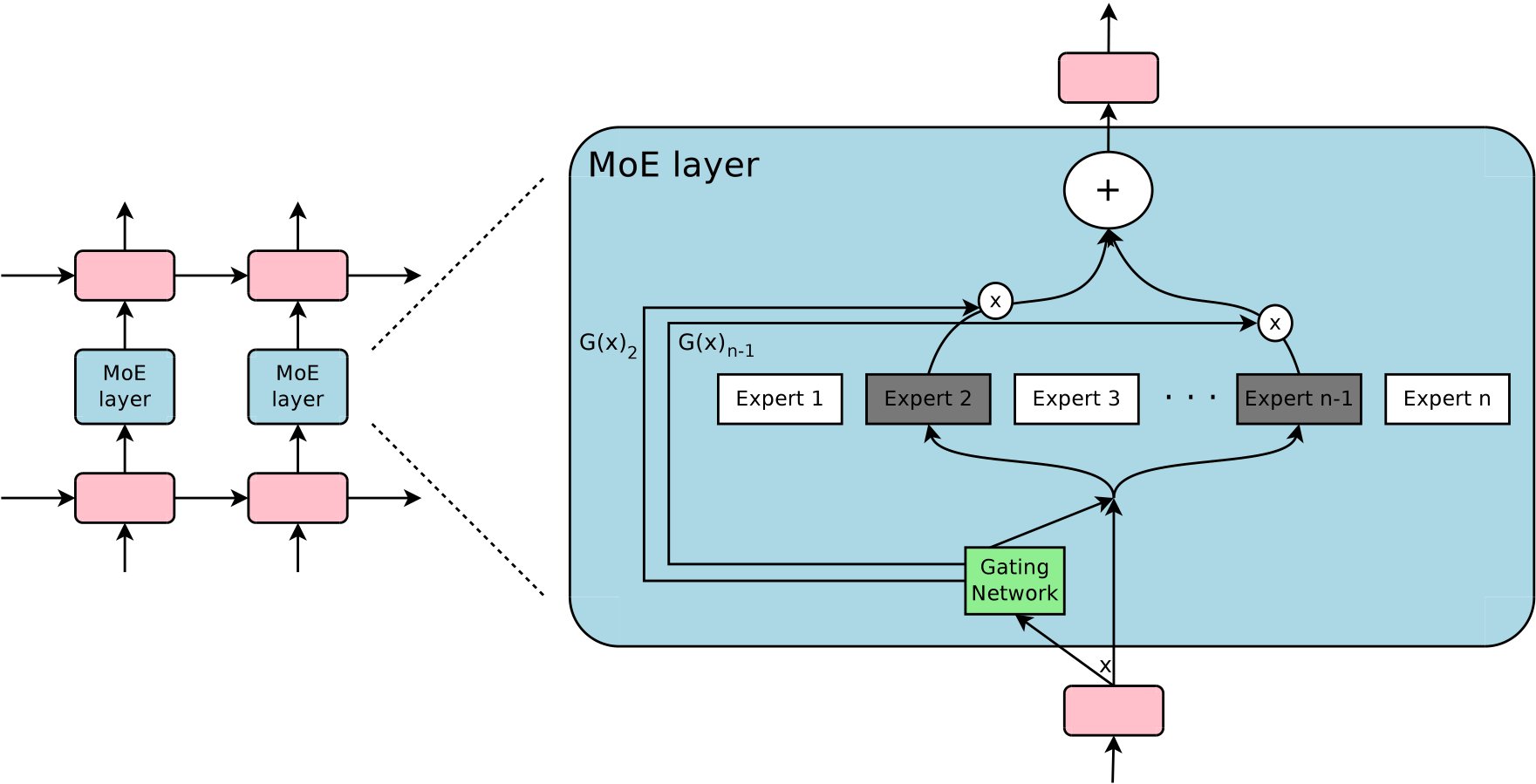
上图引用自 Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer。设 MoE 层由 $n$ 个专家网络 $E_1, \cdots, E_n$ 与一个门控网络 $G$ 组成,其中 $G$ 的输出是一个稀疏的 $n$ 维向量。给定输入 $\boldsymbol{x}$,令 $G(\boldsymbol{x})$ 和 $E_i(\boldsymbol{x})$ 分别为门控网络和第 $i$ 个专家的输出,则 MoE 层的输出 $\boldsymbol{y}$ 为被激活专家输出的加权和
$$ \boldsymbol{y}=\sum^n_{i=1}G(\boldsymbol{x})_iE_i(\boldsymbol{x}) \tag{5} $$「稀疏」体现在门控值 $G(\boldsymbol{x})_i$ 上,应有充分多的 $G(x)$ 分量 $\big\{G(\boldsymbol{x})_j\big\}$ 为 $0$,此时无需计算对应的 $\big\{E_j(\boldsymbol{x})\big\}$。原论文表示,在实验中对于上千专家的规模,每次计算也只需要评估其中个位数的专家。
如果专家规模更大,为降低计算开销可以考虑引入多级路由。以文献中设计的两级路由为例,输入首先经主门控网络,主门控网络不直接选择专家、而是选择专家组与相应的二级门控网络,随后输入再经被选中的二级门控网络,由二级门控网络再来选择具体的专家组合。
传统的门控网络是应用 Softmax 激活函数在输出层作归一化的神经网络。原论文为门控网络添加了可学习的噪声与 Top-K 稀疏化($k>1$)。记 $\mathrm{KeepTopK}(\cdot)$ 表示仅保留向量的前 $k$ 大分量并将其余分量设置为 $-\infty$(对应门控值 $0$),则
$$ G(\boldsymbol{x})=\mathrm{Softmax}\big(\mathrm{KeepTopK}(H(\boldsymbol{x}),k)\big) \tag{6} $$$$ H(\boldsymbol{x})_i=(\boldsymbol{x}\cdot\boldsymbol{W}_g)_i+\mathrm{StandardNormal}()\cdot\mathrm{Softplus}\big((\boldsymbol{x}\cdot\boldsymbol{W}_{\text{noise}})_i\big) \tag{7} $$其中 $\boldsymbol{W}_g,\boldsymbol{W}_{\text{noise}}$ 均为可学习的参数矩阵,分别为门控网络的参数矩阵与可学习噪声的参数矩阵。
在原论文中,通过这一稀疏门控的设计,在数千个专家的规模下每次评估都只需要激活个位数专家,这使得模型训练时的计算量大大降低。
$\mathrm{Softplus}(x)=\ln(1+e^x)$,输出为正实数、导数为 Sigmoid,常用于科学系参数化噪声幅度的激活函数。ReLU 可视为其更易计算的不光滑替代。
此外,原论文还设计了重要性损失与负载损失,目的是鼓励门控网络均衡地利用所有专家,防止少数专家被过度使用。原论文提到,在传统损失下容易观察到门控网络倾向于收敛到对相同的少数专家产生大权重的状态。
换言之,是为了避免「强者恒强」的「马太效应」。
原论文定义专家门相对于一批训练样本的重要性为该专家门控值的批量求和
$$ \mathrm{Importance}(\boldsymbol{X})=\sum_{\boldsymbol{x}\in\boldsymbol{X}}G(\boldsymbol{x}) \tag{8} $$设计重要性损失为重要性的变异系数的平方乘以一个手动调节的缩放因子 $w_{\text{importance}}$,即
$$ \mathcal{L}_{\text{importance}}(\boldsymbol{X})=w_{\text{importance}}\mathrm{CV}\big(\mathrm{Importance}(\boldsymbol{X})\big)^2 \tag{9} $$重要性损失考虑了所有专家的同等重要性,但每个专家接收的样本数量依然可能差异较大。为使专家对样本负载均衡,原论文设计了第二种损失 $\mathcal{L}_{\text{load}}$。定义负载
$$ \mathrm{Load}(\boldsymbol{X})_i=\sum_{\boldsymbol{x}\in\boldsymbol{X}}P(\boldsymbol{x},i) \tag{10} $$其中 $P(\boldsymbol{x},i)$ 为保持其他专家的噪声值不变,仅对专家 $i$ 的噪声进行重新随机采样的条件下,专家 $i$ 的门控值 $G(x)_i$ 非零的概率。记 $\text{kth\_excluding}(\boldsymbol{v},k,i)$ 表示从向量 $\boldsymbol{v}$ 排除第 $i$ 个分量后的第 $k$ 大的值,有
$$ P(\boldsymbol{x},i)=\varPhi\Big(\frac{(\boldsymbol{x}\cdot\boldsymbol{W}_g)_i-\text{kth\_excluding}\big(H(\boldsymbol{x}),k,i\big)}{\mathrm{Softplus}((\boldsymbol{x}\cdot\boldsymbol{W}_{\text{noise}})_i)}\Big) \tag{11} $$则负载损失 $\mathcal{L}_{\text{load}}$ 为负载的变异系数的平方乘以一个手动调节的缩放因子 $w_{\text{load}}$,即
$$ \mathcal{L}_{\text{load}}=w_{\text{load}}\cdot\mathrm{CV}\big(\mathrm{Load}(\boldsymbol{X})\big)^2 \tag{12} $$通过修改损失函数惩罚模型以软约束 MoE 负载均衡是一个经典技巧,但不是唯一方案。2021 年 BASE Layers: Simplifying Training of Large, Sparse Models 就引入了近似线性分配思想,尝试从优化角度实现结构上硬约束的严格平衡负载,不过由于计算复杂、无法高效利用计算卡,未能成为今日大模型训练的主流设计。
然而,该论文所提出的 Top-K 路由方案存在两个本质缺陷:
- Top-K 稀疏化操作 $\mathrm{KeepTopK}(\cdot,k)$ 是一种离散选择的操作,对应的阶跃函数 $m_i=\left\{\begin{aligned}&1,&&i\in\text{TopK}\\&0,&&i\notin\text{TopK}\end{aligned}\right.$ 与截断操作 $m_i\boldsymbol{h}_i+(1-m_i)(-\infty)$ 是不可微的;
- 理论上,为使梯度能够顺利回流至门控网络,通常需要要求 $k>1$,让被选中的 $k$ 个专家承载非零门控值,从而为梯度的反向传播提供路径。
第一点是显然的,严格讲 Top-K 稀疏化在数学上是不可微的,因此在实际的反向传播算法实现中通常不会直接对离散 Top-K 操作求导,而是采用近似梯度传播策略。例如,仅对被选中的非零门控值回传梯度,或采用 Straight-Through Estimator(STE)等方法,将离散路由近似视为恒等映射以回传误差。
第二点我们可以通过推导梯度加以证明。记 $\boldsymbol{z}=\mathrm{KeepTopK}\big(H(\boldsymbol{x}),k\big)$ 为 Top-K 截断后的 logits,$\boldsymbol{p}=\mathrm{Softmax}(\boldsymbol{z})=\frac{e^{\boldsymbol{z}}}{\boldsymbol{1}^{\top}e^{\boldsymbol{z}}}$ 为对应的门控值,则
$$ \begin{aligned} \mathrm{d}\boldsymbol{p}&=\frac{\mathrm{diag}(e^{\boldsymbol{z}})\mathrm{d}\boldsymbol{z}}{\mathbf{1}^{\mathsf{T}}e^{\boldsymbol{z}}}-\frac{e^{\boldsymbol{z}}\bigl(\mathbf{1}^{\mathsf{T}}\mathrm{diag}(e^{\boldsymbol{z}})\mathrm{d}\boldsymbol{z}\bigr)}{(\mathbf{1}^{\mathsf{T}}e^{\boldsymbol{z}})^2}\\ &=\mathrm{diag}(\boldsymbol{p})\mathrm{d}\boldsymbol{z}-\boldsymbol{p}\bigl(\boldsymbol{p}^{\mathsf{T}}\mathrm{d}\boldsymbol{z}\bigr)\\ &=\bigl[\mathrm{diag}(\boldsymbol{p})-\boldsymbol{p}\boldsymbol{p}^{\mathsf{T}}\bigr]\mathrm{d}\boldsymbol{z} \end{aligned} \tag{13} $$因此 Softmax 的 Jacobian 为
$$ \frac{\partial\boldsymbol{p}}{\partial\boldsymbol{z}}=\mathrm{diag}(\boldsymbol{p})-\boldsymbol{p}\boldsymbol{p}^{\mathsf{T}}\ \Leftrightarrow\ \frac{\partial\boldsymbol{p}_i}{\partial\boldsymbol{z}_j}=\boldsymbol{p}_i(\delta_{ij}-\boldsymbol{p}_j) \tag{14} $$这带来两个推论:
当 $k>1$ 时,对于被截断为 $-\infty$ 的分量 $\boldsymbol{p}_j=\mathrm{Softmax}(-\infty)=0$,代入上式有 $\frac{\partial\boldsymbol{p}_i}{\partial\boldsymbol{z}_j}=0$——这意味着被截断分量对 $\boldsymbol{W}_g$ 的梯度贡献恒为零,而前 $k$ 大的分量保持 $p_i > 0$,梯度从而得以经这些路径反向传播至 $\boldsymbol{W}_g$;
当 $k=1$ 时,所有分量的梯度均恒为 $0$。对于被截断的分量而言这是平凡的结论,假设唯一未被截断的分量为 $\boldsymbol{p}_i=1$,则
$$ \frac{\partial\boldsymbol{p}_i}{\partial\boldsymbol{z}_i} = \boldsymbol{p}_i(1-\boldsymbol{p}_i)=0,\quad \frac{\partial\boldsymbol{p}_i}{\partial\boldsymbol{z}_j} = \boldsymbol{p}_i\times0=0 \tag{15} $$因此 $k=1$ 时有 $\frac{\partial\boldsymbol{p}}{\partial\boldsymbol{z}}=\boldsymbol{0}$。这意味着在严格数学意义下,经 Top-1 路由后的 Softmax Jacobian 已完全退化,门控值对 logits 不再具有局部敏感性,梯度无法经由任何门控值反向传播至门控网络参数。这正是原论文中指出 $k$ 理论上应为正整数的原因。
在实际工程实现中,通常需要借助 STE、噪声路由、辅助负载均衡损失等技巧近似训练 $k=1$ 的离散选择过程。后续 2021 年关于 Switch Transformer 的研究便证明了通过合理的改造,Top-1 路由也是可行的设计。
参考文献:
- Shazeer, Noam, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc V. Le, Geoffrey E. Hinton and Jeff Dean. “Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer.” ArXiv abs/1701.06538 (2017): n. pag.
- Lewis, Mike, Shruti Bhosale, Tim Dettmers, Naman Goyal and Luke Zettlemoyer. “BASE Layers: Simplifying Training of Large, Sparse Models.” ArXiv abs/2103.16716 (2021): n. pag.
2020. MoE-Transformer
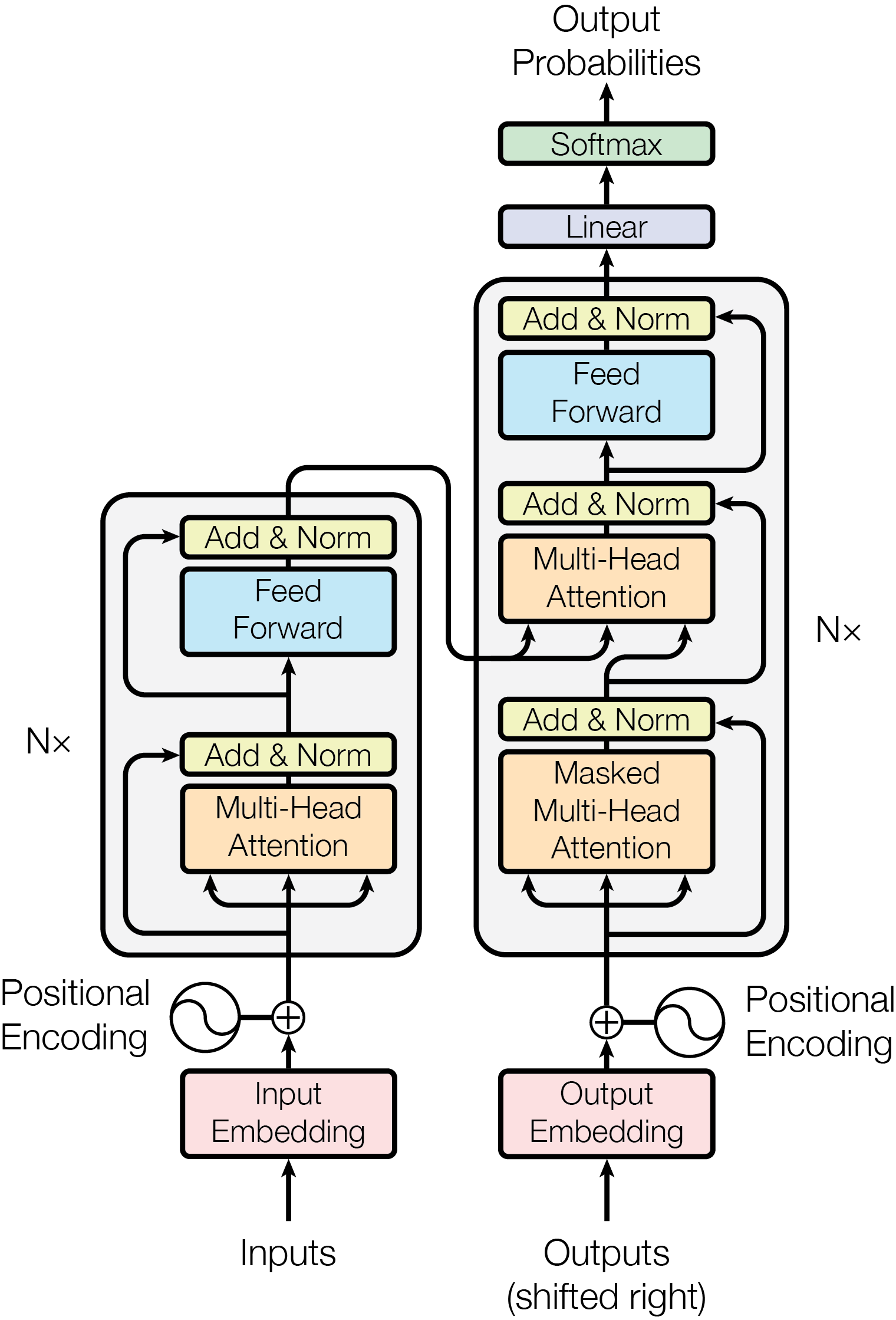
Transformer 诞生于 2017 年 Google Brain 的开创性研究 Attention Is All You Need。在前文 经典注意力与经典 Transformer 的数学原理 中系统推导并分析了经典 Transformer。粗糙地讲,经典 Transformer 的各层均为 FFN 子层与多头自注意力子层的组合。下图引用自 Attention Is All You Need。
2020 年,Google Brain 发布了首个将(稀疏门控)MoE 与 Transformer 相结合的模型 / 框架:GShard。
Noam Shazeer 同时是 2017 年 Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer 与 2020 年 GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding 的署名作者。Noam Shazeer 之于 Google,有点像喜多郁代之于纽带乐队。
GShard 为业界提供了巨大的理论贡献与工程实践经验。GShard 的论文于当年 6 月 30 日发表,而 OpenAI 在一个月前的 5 月 29 日发表了 GPT-3 的论文。GPT-3 依然是典型的稠密模型,在 2022 年年底推出并吸引来全世界注意力的 GPT-3.5 也依然是标准的稠密模型。但随后 GPT-4 也转向 MoE,本质原因是「大」是有效的,然而受限于计算机软硬件的发展,(稠密)模型不可能一直「大」下去。这也再次印证,MoE 是今天大模型领域十分关键的技术。
GShard 最核心的理论创新是将经典 Transformer 的 FFN 子层替换为了以 FFN 作为专家网络、以 Top-2 稀疏门控网络的 MoE 子层,其余理论创新多是围绕这一点展开的。关于 MoE 子层的数学表达式在上一节中已经给出,这里不再赘述。
$$ \text{combine}_{s,E}=\text{GATE}(\boldsymbol{x}_s) \tag{16} $$$$ \text{FFN}_e(\boldsymbol{x}_s)=\boldsymbol{W}^O_e\cdot\text{ReLU}(\boldsymbol{W}^I_e\cdot \boldsymbol{x}_s) \tag{17} $$$$ \boldsymbol{y}_s=\sum^E_{e=1}\text{combine}_{s,e}\cdot\text{FFN}_e(\boldsymbol{x}_s) \tag{18} $$其中 $x_s$ 是 MoE 层的输入 token,$W^I$ 和 $W^O$ 是 FFN 专家的输入和输出投影矩阵。向量 $\text{combine}_{s,E}$ 由门控网络计算得出,对每个专家输出一个非负值,且大多数为零,意味着 token 不必被分发到这部分专家。门控网络输出 Top-2 稀疏化,即每个 token 至多被分发给两个专家。
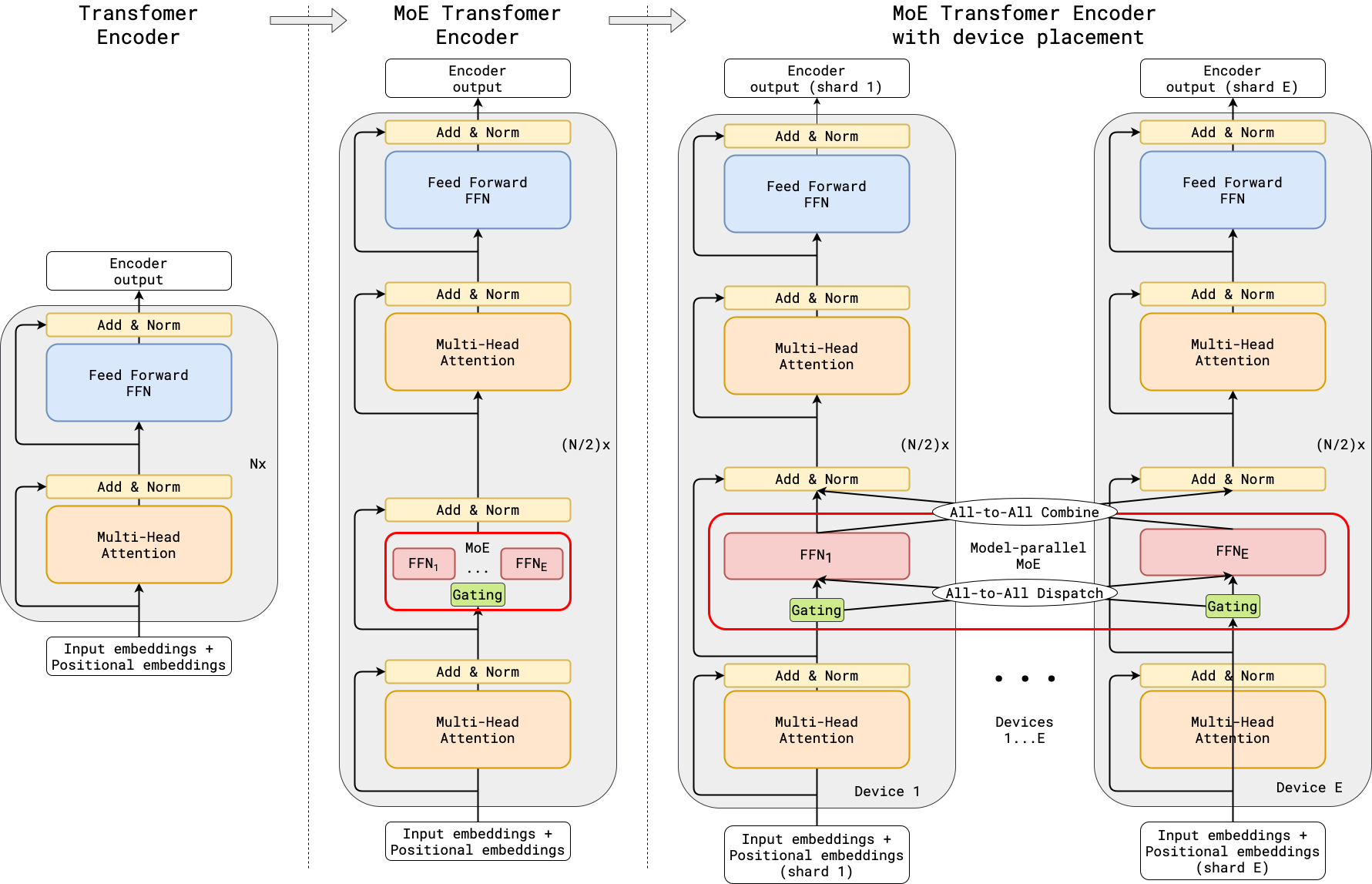
Transformer 中原本的 FFN 子层,被逐层替换为独立的 MoE 子层,且不同层的 MoE 之间没有直接参数联系,也不存在跨层路由。
实现 MoE-Transformer 并不只有将所有 FFN 都替换为 MoE 这一种做法。例如,2021 年的 GLaM(参见 GLaM: Efficient Scaling of Language Models with Mixture-of-Experts)就采取了交替层设计,Dense FFN 与 MoE FFN 交替出现。
今天的主流 Transformer-based 大模型中,MoE 层基本都用于替换传统架构中的 FFN,而非注意力层。这是一个值得思考的问题:为什么 MoE 通常被用于替换 FFN 子层?替换注意力子层是否可行?
FFN 层通常拥有更重量级的参数规模,多头自注意力层的参数量相对较少,因此用 MoE 替换 FFN 层能够在保持激活参数量不变的前提下显著提升总参数量,相比之下替换多头自注意力层则收益较小;
FFN 上的计算属于计算密集型任务,时间复杂度为 $O(nd^2)$,而得益于 KV Cache 的存在,计算自注意力的算力需求相对较小,时间复杂度为 $O(n^2d)$,相比之下,多头自注意力的核心瓶颈更多来自序列长度带来的 token 间交互计算与 KV Cache 的存储压力,而不是参数规模本身;
FFN 对每个 token 都是独立处理的,注意力则需要计算 token 间的交互关系。在我看来,多头注意力的设计本身就和稠密 MoE 有共通之处,Attention Is All You Need 就指出,多头注意力本身便存在「专业化」的倾向。
后文将提到,Switch Transformer 论文在附录中给出了将 MoE 应用在注意力上的尝试结果,数据表明这样做能够带来性能提升,但在低精度下训练是十分不稳定的,关于这一点在下一章中给出了具体的数值分析以说明原因。除非能够彻底解决混合精度下训练稳定性的问题,否则这将是制约 MoE 应用在注意力层的重大难题。
为了顺利将 FFN 层替换为 MoE 层,GShard 还做了大量工作。论文指出,门控函数 $\text{GATE}(\cdot)$ 需要满足如下两个目标:
负载均衡:在 2017 年的稀疏门控论文 Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer 中就提到了使用传统损失函数将导致少数专家被过度使用。当时的论文通过修改损失函数尝试解决这一问题,GShard 则做了更多工作以得到更稳定的系统。
规模效率:考虑到门控函数的计算复杂度,需要高效的并行实现。记 token 数为 $N$、专家数为 $E$,则门控函数计算的时间复杂度至少为 $O(NE)$,顺序实现是难以接受的。
为此,论文设计了以下四个重要机制:
Expert Capacity:为确保负载均衡,要求每个专家在一个训练 batch 中处理的 token 不得超过专家容量。如果专家已处理 token 超过专家容量,则丢弃本该分配至该专家的 token,直接将 $\text{combine}_{s,E}$ 置 $0$ 并通过残差连接跳过该 MoE 层。
Local Group Dispatching:$\text{GATE}(\cdot)$ 将训练 batch 中的所有 token 均匀地划分为 $G$ 组,每组独立并行处理。
Auxiliary Loss:定义辅助损失 $\ell_{aux}$ 用以强制门控网络多样化其选择,将辅助损失乘系数 $k$ 加入到原损失中。记 $\frac{c_e}{S}$ 为 token 被路由到每个专家的输入比例、$m_e$ 为每个专家的平均门控值,则
$$ \mathcal{L}=\ell_{nll}+k\cdot\ell_{aux} \tag{19} $$$$ \ell_{aux}=\frac{1}{E}\sum^E_{e=1}\frac{c_e}{S}\cdot m_e \tag{20} $$Random Routing:Token 必定被路由至门控值最大的专家,同时以一个同 $g_2$ 成比例的概率被随机路由至门控值第二大的专家。文献认为第二专家采用随机化路由能够降低固定 Top-2 分配所带来的专家拥塞问题,从而提高专家容量利用率。
GShard 论文所没有指出的是稀疏离散路由将导致训练的不稳定性。以现在的观点看,GShard 至少有如下三个显著缺陷:
- Top-2 路由导致 All-to-All 的跨设备通信灾难。在分布式计算集群中,专家们往往分布在不同的计算设备上,Top-2 路由将一个 token 分发至最多两个专家,这将引发海量的跨节点 All-to-All 通信,迅速消耗掉可用的通信网络带宽。在 Switch Transformer 的论文中,作者提到在 2017 年 Shazeer 等人的研究中曾推测 $k>1$ 个专家是必要的,以便路由函数具有非平凡的梯度;2018 年 Ramachandran 和 Le 的研究则表示多层路由模型中较低层的 $k$ 应取一个较大值——这些或许是 GShard 采用 Top-2 稀疏路由的原因。
- 由于 GShard 的专家容量设计,部分 token 被直接丢弃,没有被 MoE 有效利用。
- 后续研究表明,稀疏门控网络在低精度训练下容易出现数值不稳定问题,而当模型规模进一步扩大时,这一问题会变得更加突出。GShard 没有考虑并解决这一问题,而是在全流程使用昂贵的 float32 精度进行训练。这当然绕开了 bfloat16 精度下 MoE-Transformer 训练极易发散的情况,但付出的计算成本也是极为海量的。
以上三点将在随后的 Switch Transformer 得到有效改进。
参考文献:
- Lepikhin, Dmitry, HyoukJoong Lee, Yuanzhong Xu, Dehao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer and Z. Chen. “GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding.” ArXiv abs/2006.16668 (2020): n. pag.
- Du, Nan, Yanping Huang, Andrew M. Dai, Simon Tong, Dmitry Lepikhin, Yuanzhong Xu, Maxim Krikun, Yanqi Zhou, Adams Wei Yu, Orhan Firat, Barret Zoph, Liam Fedus, Maarten Bosma, Zongwei Zhou, Tao Wang, Yu Emma Wang, Kellie Webster, Marie Pellat, Kevin Robinson, Kathleen S. Meier-Hellstern, Toju Duke, Lucas Dixon, Kun Zhang, Quoc V. Le, Yonghui Wu, Z. Chen and Claire Cui. “GLaM: Efficient Scaling of Language Models with Mixture-of-Experts.” International Conference on Machine Learning (2021).
2021. Switch Transformer
GShard 验证了 MoE with Transformer 在工业领域的可行性,而 2021 年 1 月 Google Brain 正式发表的 Switch Transformer 论文 Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity 则在 GShard 的基础上将 MoE-Transformer 推向了可大规模推广实践的高潮,使得 MoE-Transformer 真正可大规模工程化。
Switch Transformer 有两点重要的历史贡献:
- 简化并改进了稀疏 MoE,将 GShard 的 Top-2 稀疏路由 MoE 调整为 Top-1 稀疏路由 MoE,同时调整了 MoE 层的顺序结构,证明了通过合理的调整、初始化与训练策略,Top-1 专家路由也是能够稳定收敛的,降低了分布式计算集群的「All-to-All」跨设备通信压力;
- 首次成功以 selective precision 训练了超大规模的稀疏 MoE,验证了 MoE-Transformer 在低精度上训练不稳定的现象与 router 密切相关,从而能够使用混合精度(float32 / bfloat16)更高效地对模型进行训练与推理。
Switch Transformer 的内容主要是基于 GShard 的改进。其中,第二点是更有价值的工作,使得 MoE-Transformer 真正获得了高效而稳定训练的能力。
这篇论文将此前主流的 Top-K 稀疏门控称为 Mixture of Expert Routing($k>1$),与之相对的是原论文的 Switch Routing——这也是「Switch Transformer」名称的由来。Switch Routing 的特征是 Top-1 稀疏路由,对每个 token 仅路由至单个专家。文献称这种 MoE 层为 Switch 层,这直接带来两个好处:
- 专家容量至少能够缩小一倍;
- 简化了路由实现,每个 token 仅需要路由至一个专家,All-to-All 通信成本大大降低。
然而,上文在数学上证明了 Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer 中的 Top-K 稀疏门控设计在 $k=1$ 时 Softmax 的 Jacobian 是完全退化的,理论上误差无法顺利传播至下层结构。Switch Transformer 的做法是交换 Softmax 与 Top-K 稀疏化的顺序。
Mixture of Expert Routing 的结构为
$$ \mathrm{Softmax}\big(\mathrm{KeepTopK}(\cdots)\big) \tag{21} $$而交换 Softmax 与 Top-1 稀疏化顺序后的 Switch Routing 的结构为
$$ \boldsymbol{p}=\mathrm{Softmax}(\cdots),\quad i^{\ast}=\arg\max_i\boldsymbol{p}_i \tag{22} $$可见,尽管在 Switch Routing 中前向传播中的 dispatch 仍是离散的 Top-1 路由,但 router 的概率输出本身是连续且可微的。代入至上文所推导出的公式
$$ \frac{\partial\boldsymbol{p}_i}{\partial\boldsymbol{z}_j}=\boldsymbol{p}_i(\delta_{ij}-\boldsymbol{p}_j) \tag{23} $$由于 $\{\boldsymbol{p}_i\}$ 是 Top-1 路由前由 Softmax 计算得到的连续概率值,因此 Softmax 的 Jacobian 不再像传统 Top-1 稀疏化后直接退化为零矩阵,从而使梯度能够继续经由 $\boldsymbol{p}$ 反向传播至门控网络参数。
根据上式,我们可以从梯度流动的视角得到如下重要差异:
在传统 Top-k 稀疏化的设计中,只有前 $k$ 大的门控值为误差传播贡献梯度,其余门控值为 $0$,不传递任何梯度;
而在 Switch Routing 中,被选中的专家路由节点 $i^{\ast}$ 通常具有正梯度 $\frac{\partial\boldsymbol{p}_{i^{\ast}}}{\partial\boldsymbol{z}_{i^{\ast}}}=\boldsymbol{p}_{i^{\ast}}(1-\boldsymbol{p}_{i^{\ast}})>0$,从而对门控权重参数有正向激励贡献;未被选中的专家路由节点 $i'$ 通常具有负梯度 $\frac{\partial\boldsymbol{p}_{i^{\ast}}}{\partial\boldsymbol{z}_{i'}}=-\boldsymbol{p}_{i^{\ast}}\boldsymbol{p}_{i'}<0$,从而对门控权重参数有负向抑制贡献。这意味着被选中的路由概率 $\boldsymbol{p}_{i^{\ast}}$ 在数学上仍耦合了所有路由节点的 logit 信息。
因此,在 Switch Routing 的设计下来自上层的梯度 $\frac{\partial\mathcal{L}}{\partial\boldsymbol{p}_{i^{\ast}}}$ 可以通过非零的 Jacobian 矩阵连续且平滑地分配给所有门控网络参数。
这里的思想是「dispatch 不可导 ≠ routing probability 不可导」。故可以使 routing probability 指导 dispatch,但不直接对 dispatch 求导,而是对 routing probability 求导,因为 Switch 的训练并不依赖 dispatch 的梯度。
后来的 DeepSeekMoE 也使用了类似 Switch 的顺序设计,这的确是一个很有价值的改进。
除了这一点调整外,Switch Transformer 在 MoE 层(或在此称为 Switch 层)完全继承了 GShard 的专家容量的概念以及对 token drop 的行为(尽管文献表示丢弃率较低,对模型的影响很小),也基本继承了 GShard 的负载均衡 Auxiliary Loss 设计,这里就不展开赘述了。
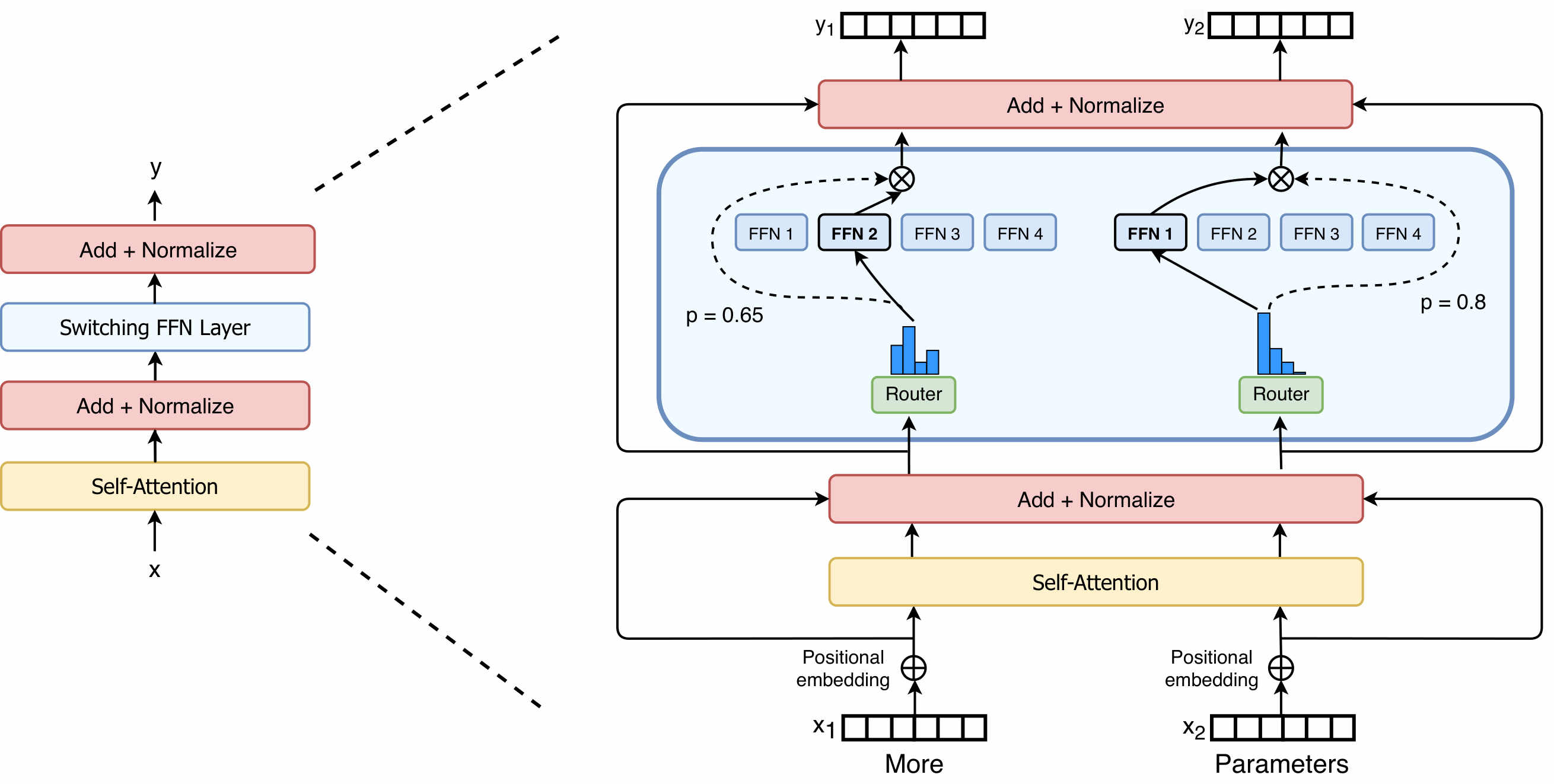
Top-1 不一定是最优解,只不过 Switch Transformer 的出现表明 Top-1 也是可行的。
过去,MoE-Transformer 存在训练不稳定的难题。Switch Transformer 通过创新训练与微调技术——Selective Precision(选择性精度),解决了稀疏路由导致训练发散的问题。
文献指出,MoE-Transformer 的训练时使用低精度 bfloat16 可能导致发散的不稳定现象,有可能源于每层的路由决策。更进一步讲,router 中 Softmax 的计算中存在指数函数,指数函数对精度敏感,这可能是导致低精度训练模型困难的原因之一。
具体而言,bfloat16 采用 1-8-7 位宽(符号位-指数位-尾数位),与 float32 具有相同的指数位宽(均为 8 位),但尾数仅有 7 位(float32 为 23 位),因此其 machine epsilon 约为 $2^{-7}\approx7.8\times10^{-3}$。这意味着 bfloat16 虽然保留了与 float32 接近的动态范围,但有效精度明显更低。
当 router logit $z$ 达到约 $10$ 时,$\exp(z)\approx2.2\times10^4$,此时 bfloat16 的尾数精度只能分辨约 $1.7\times10^2$ 的量级差。因此,在 Softmax 分母对多个相近大小的指数项求和时,极容易产生显著的舍入误差(roundoff error)。
另一方面,router logits 作为未经归一化的线性输出,会随隐藏维度增大与训练推进而迅速扩大数值范围,较容易进入 $[10,88]$ 的高风险区间。而当 $z$ 进一步增大至约 $88.7$ 时,$\exp(z)$ 将超过 bfloat16 的最大正规值 $\approx3.39\times10^{38}$,从而发生上溢(overflow)。
相比 GShard 在全过程选择 float32 精度,Switch Transformer 开创性地将混合精度训练策略应用在了稀疏激活模型:仅在 router 内部(自 token 输入,至 router 输出)使用 float32,在模型的其余部分,包括所有的 FFN,均使用 bfloat16。下面直接引用原论文中的表格以说明该方法的巨大价值:
| Model (precision) | Quality (Neg. Log Perp.) (↑) | Speed (Examples/sec) (↑) |
|---|---|---|
| Switch-Base (float32) | -1.718 | 1160 |
| Switch-Base (bfloat16) | -3.780 [diverged] | 1390 |
| Switch-Base (Selective precision) | -1.716 | 1390 |
可见,Selective Precision 实现了与全精度几乎一致的训练效果。通过这一方案,float32 仅在局部被使用,使得 All-to-All 通信不必再广播昂贵的 float32,即使是本地计算(而非跨设备计算集群)也能从中受益。
为了增强训练的稳定性,论文内记录了多次试验的结论,最终发现对于使用零均值截断正态分布随机变量初始化的权重矩阵,将缩放超参数($s$,用于控制方差 $\sigma^2=\frac{s}{n}$,其中 $n$ 为张量的输入单元数 fan-in)从 $1$ 减少至 $0.1$ 能够显著降低模型训练不稳定的风险。即,稀疏 MoE 对初值十分敏感,而更稳定的初值分布能够明显改善训练的质量。
| Model (Initialization scale) | Average Quality (Neg. Log Perp.) | Std. Dev. of Quality |
|---|---|---|
| Switch-Base (0.1x-init) | -2.72 | 0.01 |
| Switch-Base (1.0x-init) | -3.60 | 0.68 |
在附录中,论文还对将 MoE 引入注意力层进行了尝试。
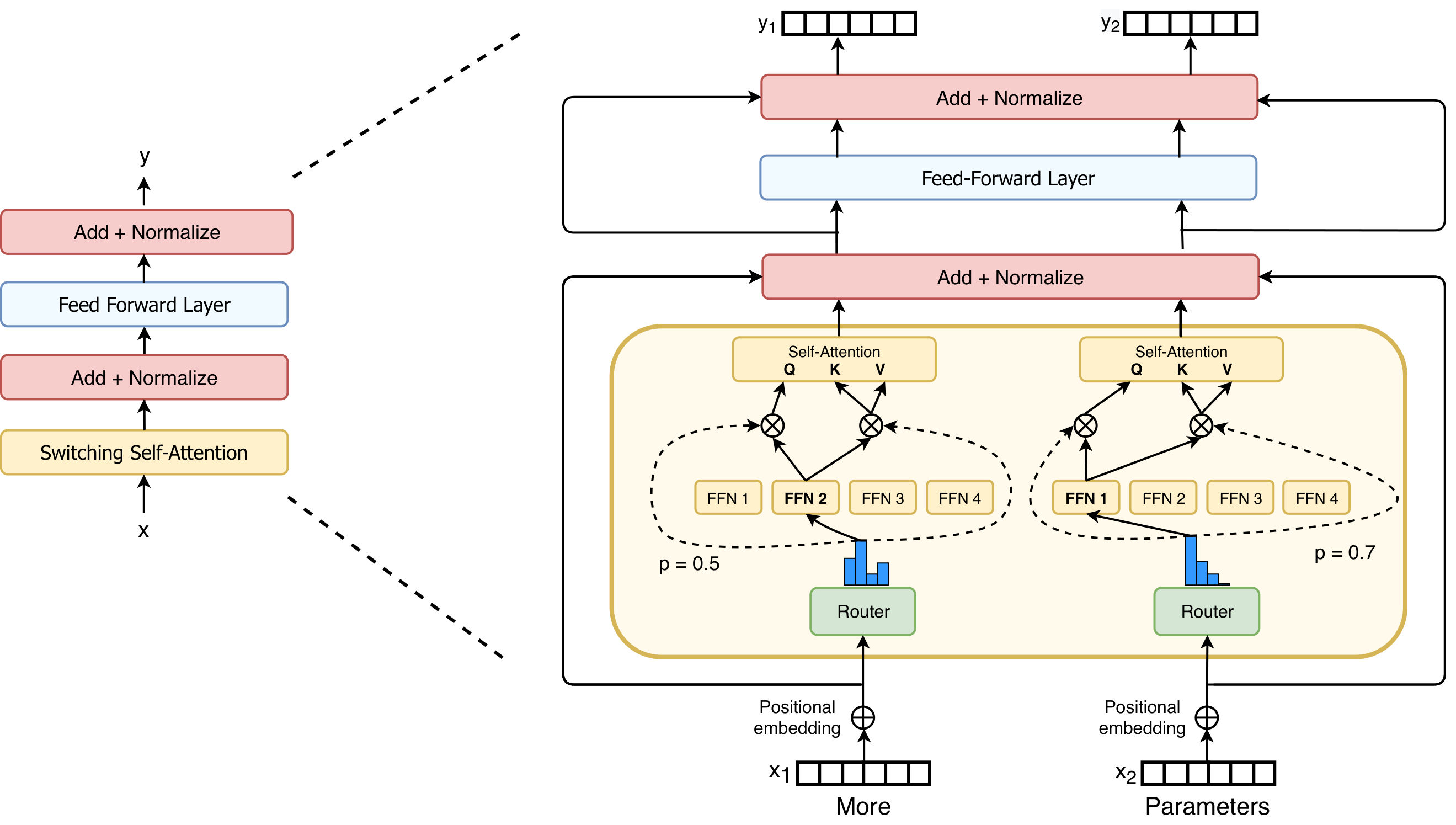
从结果上看,将 Switch 注意力引入标准的 Switch Transformer(即仅引入 Switch FFN 的 Experts FF)的确能带来一定的性能提升,但在低精度 bfloat16 下的训练是发散的。论文尝试了一些改进,但最终未能解决 bfloat16 精度下 MoE 注意力训练不稳定的问题。
| Model | Precision | Quality @100k Steps (↑) | Quality @16H (↑) | Speed (ex/sec) (↑) |
|---|---|---|---|---|
| Experts FF | float32 | -1.548 | -1.614 | 1480 |
| Expert Attention | float32 | -1.524 | -1.606 | 1330 |
| Expert Attention | bfloat16 | [diverges] | [diverges] | – |
| Experts FF + Attention | float32 | -1.513 | -1.607 | 1240 |
| Expert FF + Attention | bfloat16 | [diverges] | [diverges] | – |
参考文献:
- Fedus, William, Barret Zoph and Noam Shazeer. “Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity.” ArXiv abs/2101.03961 (2021): n. pag.
2022. ST-MoE
在 Switch Transformer 验证了 Sparse MoE 可大规模训练后,Google Brain 开始系统研究稀疏专家模型在稳定性、迁移能力(Transferability)与工业级训练中的问题,并在 ST-MoE: Designing Stable and Transferable Sparse Expert Models 中总结了这一阶段的关键工程经验。在这些经验的指导下,团队稳定地训练了一个 269B 参数规模的稀疏模型——其训练成本与 32B 的稠密模型相当。
作者里咋又有 Noam Shazeer?
文献的主要观点可被总结为以下四点:
低精度训练不稳定根因:Router 中涉及额外指数运算的 Softmax 是导致如 bfloat16 等低精度格式训练不稳定的重要原因,输入的极大 logits 值会急剧放大数据截断误差(Roundoff Errors)。为此,论文引入新辅助损失 Router Z-loss
$$ \mathcal{L}_z(\boldsymbol{x})=\frac{1}{B}\sum_{i=1}^{B}\bigg(\log\sum_{j=1}^{N}e^{\boldsymbol{x}^{(i)}_j}\bigg)^2 \tag{24} $$其中 $B$ 为 batch 中的 token 数,$N$ 为专家数,$\boldsymbol{x} \in \mathbb{R}^{B \times N}$ 为进入 router Softmax 前的原始 logits 矩阵(每行对应一个 token,每列对应一个专家)。$\log\sum\limits_{j=1}^{N} e^{\boldsymbol{x}^{(i)}_j}$ 即 LogSumExp 函数,是 max 的平滑近似——只要任意一个专家 logit 过大,该项即远离零。外层平方后对 $B$ 个 token 取平均,惩罚任意 token 产生过大 logits。
该损失的核心在于两点设计:
- 其一,LogSumExp 是 $\max_j x_j$ 的平滑近似——只要存在任意一个过大的 logit,$\log\sum e^x$ 即显著偏离零,外层平方对其施加二次惩罚,抑制尖峰(Peak)比一次惩罚更有效(对大偏差的梯度与偏差幅度成正比,迫使 logits 整体趋近零而非仅压制最大值);
- 其二,Z-loss 直接作用于进入 Softmax 之前的 logits 空间,属于 preconditioning 而非事后修正——它在优化过程中持续将 logits 约束在低幅值区间,确保 bfloat16 的 7 位尾数精度对 $\exp(z)$ 的舍入误差可控(参见上一节对 bfloat16 数值范围的讨论)。这与事后对 Softmax 输出进行截断或裁剪不同,Z-loss 不引入非平滑操作,因此不影响梯度流的连续性。
克服过拟合的微调(Fine-Tuning)策略:文献指出,稀疏模型在海量数据预训练时表现极佳,但在面对数据量较小的下游任务时极易过拟合,导致验证集效果不如参数更少的稠密模型。文献根据实验经验总结了微调策略:
- 冻结部分参数进行微调:实验证明,在微调时仅更新「非 MoE 参数」(Non-MoE parameters)不仅能达到与全量更新几乎一致的效果,还能大幅降低显存和计算开销。相反,仅更新 MoE 参数则会导致性能断崖式下跌;
- 反直觉的超参数设定:稀疏模型和稠密模型在微调时所需的超参数截然不同。为了引入更多噪声以对抗过拟合,稀疏模型往往需要更小的 Batch Size 和更高的学习率,这与稠密模型的最优解是完全相反的。
软硬件协同的模型架构设计:文献表示,增加专家数量并不会增加单次推理的计算开销(FLOPs),但为增加专家数量需要从设备内存中加载额外的专家权重,这会显著增加访存压力并降低计算内存比,即制约模型性能的实际瓶颈逐渐从计算转向访存与通信。为了保证算力利用率,文献建议现代计算硬件(如 GPU、TPU)上每个计算核心最多分配 1 个专家。
与此同时,在综合考虑通信成本(All-to-All / All-Reduce)和计算成本后,文献推荐采用 Top-2 路由,搭配 1.25 的训练容量因子(Capacity Factor),这在大规模分布式系统中能够达到效率与质量的帕累托最优。
路由行为与专家特化(Specialization)的可解释性:文献通过追踪 token 的路由轨迹,揭示了 MoE 黑盒内部的有趣现象:
- 编码器 Encoder 专家的分化:编码器中的专家会自发产生语义或句法层面的特化(Specialization)。例如,部分专家专门处理标点符号,有的负责动词,有的处理视觉特征描述,还有的专门处理数字或专有名词;
- 语言无关 Language-agnostic:在多语言混合预训练中,专家并没有按照语言种类进行分化。Router 会无差别地将不同语言的 token 送入各个专家,这意味着专家学习到的是跨语言的抽象特征;
- 解码器 Decoder 缺乏特化:与编码器形成鲜明对比的是,解码器的专家几乎没有展现出明显的专业化分工。
文献指出,专家的特化并非简单按照语言、任务等人工可解释维度进行分工,而更可能是训练过程中所自发形成的高维特征路由行为(Emergent Routing Behavior)。
ST-MoE 标志着稀疏 MoE 的研究重点从早期的「结构设计与可扩展性」逐渐转向工程落地。
参考文献:
- Zoph, Barret, Irwan Bello, Sameer Kumar, Nan Du, Yanping Huang, Jeff Dean, Noam Shazeer and William Fedus. “ST-MoE: Designing Stable and Transferable Sparse Expert Models.” (2022).
2022. Expert Choice Routing
2022 年以前的 MoE 架构普遍采用「token 选择专家」的路由机制,即门控网络依据输入 token 动态计算并分发 token 至特定的专家网络。这带来了负载不均衡的结构性问题,如果不做额外约束,很容易导致小部分专家过于忙碌而大部分专家几乎不被激活的现象。
2022 年的研究 Mixture-of-Experts with Expert Choice Routing 则启发了我们一种全新思路:放弃「token 选择专家」,转而让「专家选择 token」,于是便得到了 token 与专家天然负载均衡的结构,无需施加额外的辅助损失。
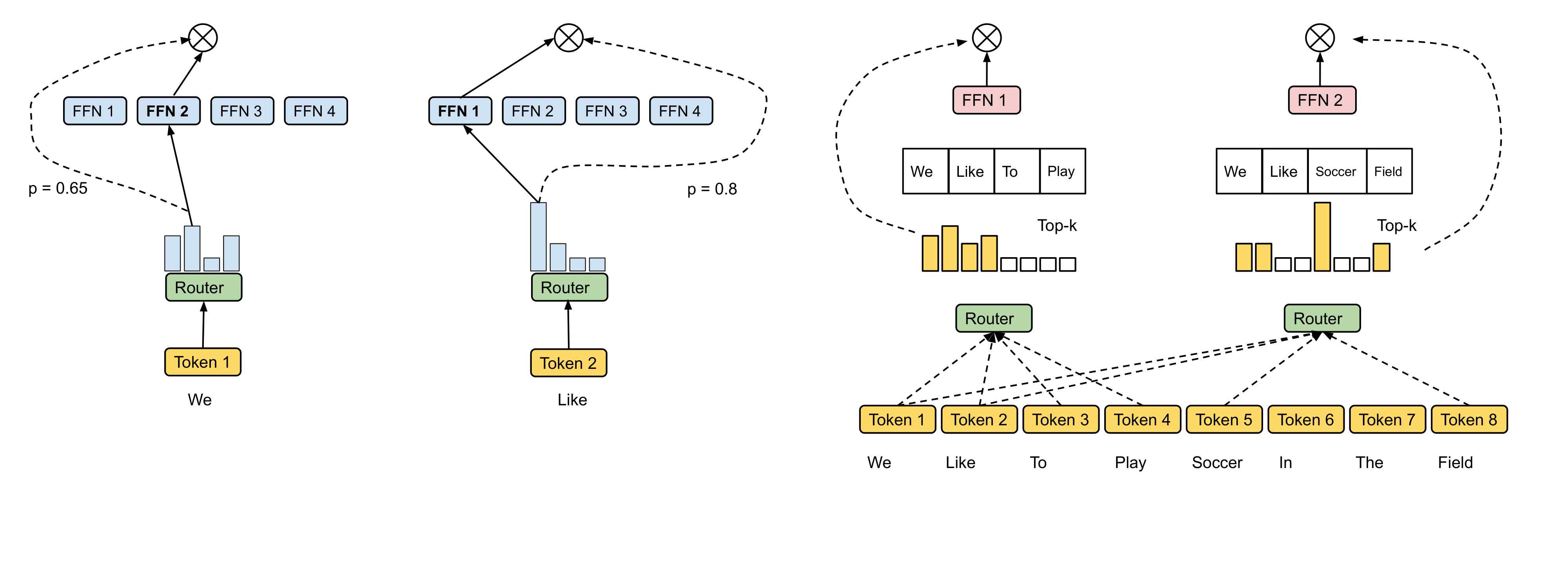
与 2021 年的 GLaM 相似的是,本文献在设计模型时也采取了将每隔一层的 FFN 替换为 MoE-FFN 的做法。
Expert Choice Routing 为我们启发了新的思路。传统的 Top-K MoE(Token Choice Routing)不可避免地使得 token 倾向于集中选择少数专家,过去的普遍做法是通过设置专家容量并为损失函数施加额外的惩罚项以软性地约束少数专家过载情况。Expert Choice Routing 通过反转选择者与被选择者的关系,从结构上精确确保了每个专家都选中 $k$ 个 token,从而实现了严格的负载均衡。
在许多系统中,这不一定是比传统 MoE 更好的方案。但它提示了我们,有时需要跳出既有上下文的思维定式,才能得到更广阔而全面的认知。
与传统路由方法不同,expert choice 为每个专家独立选择 Top-K 个 token,因此每个 expert 的负载天然固定且均衡,而 token 被分配到的 expert 数量则可动态变化。这里 $k$ 被定义为 expert choice 下的专家容量。记 $n$ 为 batch 中 token 总数(batch size × 序列长度)、$e$ 为专家数量、$c$ 为表示每个 token 平均被分发至多少个专家的超参数,原论文中考虑
$$ k=\frac{nc}{e} \tag{25} $$假设输入 token 的表示为 $\boldsymbol{X}\in\mathbb{R}^{n\times d}$($d$ 为模型隐藏维度),该方案使用三个输出矩阵 $\boldsymbol{I},\boldsymbol{G},\boldsymbol{P}$ 表征 token 至专家间的分配。$\boldsymbol{I}\in\mathbb{R}^{e\times k}$ 为索引矩阵,$\boldsymbol{I}_{ij}$ 意味着第 $i$ 个专家选择第 $j$ 个 token 的索引;$\boldsymbol{G}\in\mathbb{R}^{e\times k}$ 为各专家对所选的 $k$ 个 token 的权重;$\boldsymbol{P}\in\mathbb{R}^{e\times k\times n}$ 则是 $\boldsymbol{I}$ 的 one-hot 形式。三个输出矩阵通过下述门控函数进行计算:
$$ \boldsymbol{S}=\mathrm{Softmax}(\boldsymbol{X}\boldsymbol{W}_{g}),\quad\boldsymbol{S}\in\mathbb{R}^{n\times e} \tag{26} $$$$ \boldsymbol{G},\boldsymbol{I}=\mathrm{TopK}(\boldsymbol{S}^\top, k),\quad\boldsymbol{P}=\mathrm{Onehot}(\boldsymbol{I}) \tag{27} $$其中 $\boldsymbol{S}$ 表示 token 到专家的亲和度分数,$\boldsymbol{W}_g \in \mathbb{R}^{d\times e}$ 表示 expert embeddings,$\mathrm{TopK}()$ 为 $S^\top$ 的每一行选择前 $k$ 个最大条目的值及其对应索引。
Expert embeddings 是门控网络内可学习的权重矩阵。Expert embeddings 表示总共 $e$ 个专家中每个专家的 $d$ 维 embedding 向量,我们将输入 token 向量与第 $i$ 个专家的 embedding 向量的点积视为亲和度分数。
门控网络的输入 $\boldsymbol{X}_{\text{in}}=\boldsymbol{PX}\in\mathbb{R}^{e\times k\times d}$。对于 MoE 层中 experts 的参数张量 $\boldsymbol{W}_1,\boldsymbol{W}_2$,其第一维切片 $\boldsymbol{W}_1[i],\boldsymbol{W}_2[i]\in\mathbb{R}^{d\times d'}$ 分别表示第 $i$ 个 expert 的两层前馈网络参数矩阵,其中第二层线性变换通过右乘 $\boldsymbol{W}_2[i]^\top$ 实现。
于是,第 $i$ 个专家网络的输出 $\boldsymbol{X}_e[i]$ 为
$$ \boldsymbol{X}_e[i]=\mathrm{GeLU}(\boldsymbol{X}_{in}[i]\cdot\boldsymbol{W}_{1}[i]+\boldsymbol{b}_1[i])\cdot\boldsymbol{W}_{2}[i]^\top+\boldsymbol{b}_2[i] \tag{28} $$这里遵循了原文献的记号,$\boldsymbol{A}[i]$ 表示对张量 $\boldsymbol{A}$ 的第一个维度进行切片索引。$\boldsymbol{b}_1\in\mathbb{R}^{d'}$ 与 $\boldsymbol{b}_2\in\mathbb{R}^{d}$ 是可学习的偏置项,在原文献的公式中是被省略的:「We omit the bias terms here for brevity.」
最终,门控网络的输出为
$$ \boldsymbol{X}_{\text{out}}[l, d]=\sum_{i, j}\boldsymbol{P}[i,j,l]\ \boldsymbol{G}[i,j]\ \boldsymbol{X}_e[i,j,d] \tag{29} $$其中 $\boldsymbol{X}_{\text{out}} \in \mathbb{R}^{n\times d}$。
通过上述设计,可以确保每个专家固定接收 $k$ 个 token,因此专家与专家间处理的 token 数是负载均衡的。然而,在该设计下依然存在 token 被丢弃的情况——如果一个 token 没有被任何专家选中,那么该 token 将不会作为任何专家网络的输入。
参考文献:
- Zhou, Yanqi, Tao Lei, Han-Chu Liu, Nan Du, Yanping Huang, Vincent Zhao, Andrew M. Dai, Zhifeng Chen, Quoc V. Le and James Laudon. “Mixture-of-Experts with Expert Choice Routing.” ArXiv abs/2202.09368 (2022): n. pag.
2024. DeepSeekMoE
问世于 2024 年的 DeepSeekMoE 对 MoE 的后续理论发展与工业落地均产生了深远影响。在 2022 年以前,Sparse MoE 的主要公开研究长期由 Google Brain 主导;而自 2024 年起,DeepSeek 逐渐成为这一方向最活跃、最具影响力的开源研究力量之一。本章聚焦于 DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models,说明 DeepSeekMoE 的理论价值。
2024 年之前的 MoE(如 Switch、GLaM 等)实践中普遍面临「知识混杂」与「知识冗余」的问题,DeepSeekMoE 则通过「细粒度拆分」和「共享专家」打破了传统的路由范式。
知识混杂(Knowledge Hybridity):在 DeepSeekMoE 以前的 MoE 实践中专家数量通常较少(如 8 或 16 个),这使得不同语义模式或统计特征的 token 可能被迫共享同一专家参数空间,因此各专家不得不在参数中混杂学习这些差异极大的知识,最终导致专家的专业化程度不足,并且也难以被组合以高效利用。
知识冗余(Knowledge Redundancy):不同专家在处理输入 token 时可能会共同依赖某些共通的知识。因此,多个专家会在各自的参数中重复习得这些共享知识,从而造成专家参数的冗余。
为解决上述问题,DeepSeekMoE 主要完成了下述两点理论创新:
细粒度专家分割(Fine-Grained Expert Segmentation):在保持参数总量不变的前提下,将每个 FFN 专家的隐藏维度缩减为原来的 $\frac{1}{m}$,可以视为将原先的每个专家切分成了 $m$ 个更小的专家,同时每个 token 激活的专家数也同步增至原来的 $m$ 倍。这使得专家能够更加专业化,且整体计算量保持不变。
共享专家隔离(Shared Expert Isolation):指定部分专家作为始终激活的共享专家,用于捕获和整合跨不同上下文的通用知识。通过将通用知识压缩至这些共享专家中,其他路由专家之间的知识冗余得到缓解,从而提高参数效率,确保每个路由专家能够聚焦于更独特的知识方面以保持高度专业化。
注意,此处的共享专家隔离是在 token 的语义子空间上进行的,而 PLE 是在任务上进行的。
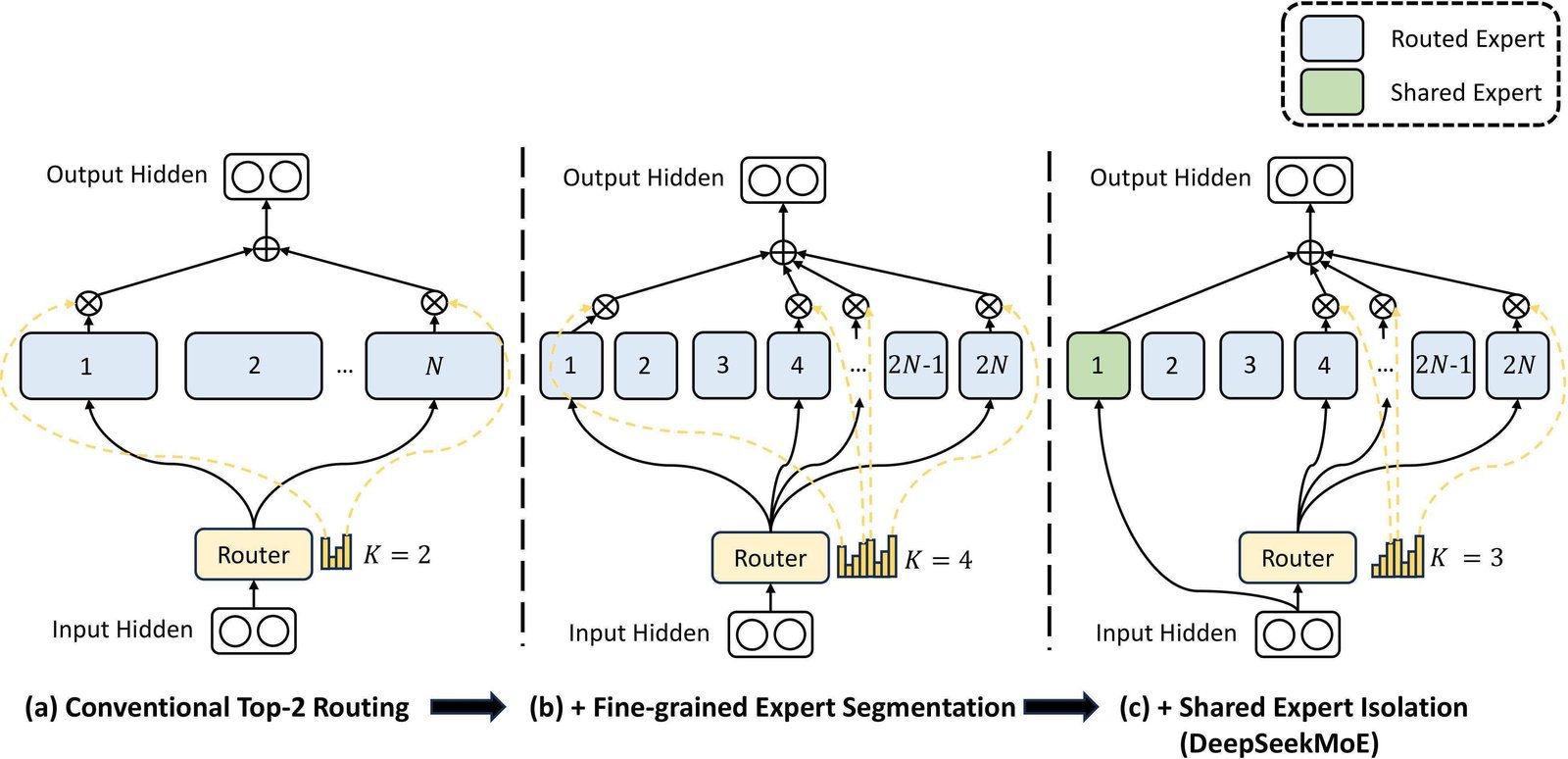
如上文所述,细粒度专家分割的思想是用更多的「小而专」专家替代原本少量的「大而泛」专家。假设(原本的)专家总数为 $N$,每个 FFN 专家网络的隐藏维度为 $d_{\text{FNN}}$,考虑 Top-K 路由,则类似 Switch 的前馈顺序结构,记 $\boldsymbol{u}_{t}^{l}$ 为 Transformer 模型第 $l$ 层针对序列的第 $t$ 位置的输入表示,$\boldsymbol{h}_{t}^{l}$ 为其对应的 MoE 子层的输出,则分割前的 MoE 子层输出为
$$ \boldsymbol{h}_{t}^{l}=\underbrace{\sum_{i=1}^{N}g_{i,t}\,\mathrm{FFN}_{i}\left(\boldsymbol{u}_{t}^{l} \right)}_{\text{sparse FFN weighted sum}}+\overbrace{\ \ \boldsymbol{u}_{t}^{l}\ \ }^{\mathclap{\substack{\text{Transformer}\\\text{residual connection}}}} \tag{30} $$$$ g_{i,t}=\left\{\begin{aligned}&s_{i,t}, && s_{i,t} \in \mathrm{Topk}\big(\{ s_{j, t}\mid1\leqslant j \leqslant N\},K\big)\\ &0,&&\text{Otherwise} \end{aligned}\right. \tag{31} $$$$ s_{i,t}=\mathrm{Softmax}_i\Big({\boldsymbol{u}_{t}^{l}}^{\top}\boldsymbol{e}_{i}^{l}\Big) \tag{32} $$忽略 activation、bias 与 routing 等开销,仅考虑主矩阵乘法,一个 FFN 专家的一次前馈传播的的浮点运算量(FLOPs)约为 $2\times d_{\text{in/out}}\times d_{\text{FNN}}$,因此分割专家前每个 token 激活 $K$ 个专家的计算量约为
$$ \text{Total FLOPs}_{\text{conventional}}=2Kd_{\text{in/out}}d_{\text{FNN}} \tag{33} $$而在将 FFN 的隐藏维度缩减为原先的 $\frac{1}{m}$ 倍后,每个 token 激活的专家数与非零门控值数量也从 $K$ 增加至 $mK$,有
$$ \boldsymbol{h}_{t}^{l}=\sum_{i=1}^{mN} g_{i,t}\,\mathrm{FFN}_{i}\left(\boldsymbol{u}_{t}^{l} \right)+\boldsymbol{u}_{t}^{l} \tag{34} $$$$ g_{i,t}=\left\{\begin{aligned} &s_{i,t},&&s_{i,t}\in\mathrm{Topk}\big(\{ s_{j, t}\mid1\leqslant j\leqslant mN \}, mK\big)\\ &0,&&\text{Otherwise} \end{aligned}\right. \tag{35} $$$$ s_{i,t}=\mathrm{Softmax}_i\Big({\boldsymbol{u}_{t}^{l}}^{\top}\boldsymbol{e}_{i}^{l}\Big) \tag{36} $$分割专家后每个专家的浮点运算量(FLOPs)约为 $\frac{1}{m}\times2\times d_{\text{in/out}}\times d_{\text{FNN}}$,每个 token 激活 $mK$ 个专家,总计算量约为
$$ \text{Total FLOPs}_{\text{segmentation}}=mK\cdot\frac{2}{m}d_{\text{in/out}}d_{\text{FNN}}=\text{Total FLOPs}_{\text{conventional}} \tag{37} $$可见,分割专家后总计算量是不变的。以 $N=16$ 个专家、Top-2 路由为例,原先每个 token 对应的可能的专家组合数仅有 $\binom{16}{2}=120$ 种;而当考虑 $m=4$(即 DeepSeek-V3 所采用的方案)时,每个 token 将从 $64$ 个小专家中选择性地激活 $8$ 个,可能的专家组合数激增至 $\binom{64}{8}=4,426,165,368$ 种,因此模型在几乎没有增加额外的计算成本的前提下,拥有了更强的表达能力。
论文中提到,Microsoft 曾在 2022 年的 DeepSpeed-MoE: Advancing Mixture-of-Experts Inference and Training to Power Next-Generation AI Scale 中于工程的视角导出了共享专家隔离的原型,而 DeepSeekMoE 则从算法的视角深入研究并最终实践了共享专家隔离机制。
具体而言,因为存在一些知识是通用的,故隔离 $K_s$ 个专家作为共享专家。无论 router 的输出如何,token 始终被分发至这些共享专家。
为了确保不增加额外的计算量,除激活的共享专家以外被 Top-K 路由激活的专家数量应调整为 $mK-K_s$,调整后的 MoE 子层表达式为
$$ \boldsymbol{h}_{t}^{l}=\sum_{i=1}^{K_{s}}\mathrm{FFN}_{i}\left(\boldsymbol{u}_{t}^{l}\right)+\sum_{i=K_{s}+1}^{mN}g_{i,t}\mathrm{FFN}_{i}\left(\boldsymbol{u}_{t}^{l}\right)+\boldsymbol{u}_{t}^{l} \tag{38} $$$$ g_{i,t}=\left\{\begin{aligned} &s_{i,t},&&s_{i,t}\in\mathrm{Topk}\big(\{s_{j, t}\mid K_{s} < j\leqslant mN\},mK-K_{s}\big)\\ &0,&&\text{Otherwise} \end{aligned}\right. \tag{39} $$$$ s_{i,t}=\mathrm{Softmax}_i\Big({\boldsymbol{u}_{t}^{l}}^{\top}\boldsymbol{e}_{i}^{l}\Big) \tag{40} $$前述的细粒度分割与共享隔离机制主要解决了参数分配与知识学习的效率问题。然而,在分布式系统下,工业级 MoE 模型的训练还面临着严峻的硬件通信挑战。即使 expert-level routing 已相对均衡、token 已被相对均匀地分发至各专家,一旦多个高负载专家恰好部署于同一计算设备,仍可能导致训练过程中出现计算瓶颈与 All-to-All 通信开销的急剧上升。
为缓解分布式训练中的设备负载不均问题,DeepSeekMoE 在传统的 expert-level auxiliary loss 基础上进一步提出了 device-level balance loss。若将所有路由专家划分为 $D$ 组 $\{\mathcal{E}_1,\mathcal{E}_2,\dots,\mathcal{E}_D\}$ 并将每组部署在单个设备上,则 device-level balance loss $\mathcal{L}_{\mathrm{DevBal}}$ 被定义为
$$ \mathcal{L}_{\mathrm{DevBal}}=\alpha_{2}\sum_{i=1}^{D}f_i^{\prime}P_i^{\prime} \tag{41} $$$$ f_i^{\prime}=\frac{1}{|\mathcal{E}_i|}\sum_{j\in\mathcal{E}_i}f_j \tag{42} $$$$ P_i^{\prime}=\sum_{j\in\mathcal{E}_i}P_j \tag{43} $$其中 $\alpha_{2}$ 是 device-level 均衡因子的超参数,$f_j$ 表示路由至专家 $j$ 的 token 占比,$P_j$ 表示专家 $j$ 在门控 softmax 输出中的平均概率。在此基础上,$f_i^{\prime}$ 为第 $i$ 组设备内所有路由专家的平均 token 负载,$P_i^{\prime}$ 为该组内所有路由专家的平均门控概率之和。
引入 device-level balance loss 可能会削弱 expert-level auxiliary loss 对 expert-level routing 负载均衡的约束效力,但论文认为这是有必要的,因为对负载均衡的过度约束会损害模型性能。在实践中,DeepSeek 团队选择设置较小的传统 expert-level auxiliary loss 惩罚与较大的 device-level balance loss 惩罚。
部分后续研究从实证角度进一步支持了 DeepSeekMoE 的设计路线。
2024 年,DeepSeek 团队在专家级微调(ESFT)的相关论文 Let the Expert Stick to His Last: Expert-Specialized Fine-Tuning for Sparse Architectural Large Language Models 研究了 MoE 模型在微调阶段的参数效率,明确指出细粒度专家模型在选择与下游任务最相关的专家组合时更具优势,从而提升训练效率与效果。
同年,Olson 等人在 Probing Semantic Routing in Large Mixture-of-Expert Models 以第三方研究者的身份进行了实证检验,观察到少专家模型较难形成稳定、细粒度的语义路由模式,同时也观察到了若干支持 MoE routing 与语义有相关性的证据。研究指出,早期拥有少量专家(8 到 32 个)的模型可能没有足够的表达能力来捕捉细粒度的专业化模式,即难以克服「知识混杂」问题。该论文在对比多个开源模型后明确得出结论,DeepSeek 展现出了最清晰且最一致的语义相关路由模式,印证了 DeepSeekMoE 设计的合理性。
2025 年,Park 等人在 How Many Experts Are Enough? Towards Optimal Semantic Specialization for Mixture-of-Experts 中从动态扩展的角度证明了扩充专家数量以细化语义分工的必要性。该论文指出,传统的 MoE 经常忽视专家间细粒度的语义专业化,而这正是「最小化专家功能冗余」的关键。论文提出,当专家在语义上超载时,必须增加专家数量。
2026 年,Hu 等人在 Synergistic Intra- and Cross-Layer Regularization Losses for MoE Expert Specialization 证实「专家重叠 / 知识冗余」是行业痛点,且共享专家架构具有极高的兼容性。该论文明确指出,稀疏 MoE 模型饱受「专家重叠」(expert overlap)——即专家间冗余的表征与路由歧义的困扰,导致模型容量未被充分利用。为了解决这个问题,他们提出了正则化损失来鼓励专家学习互补的知识。值得注意的是,他们特别强调了其方法能够完美兼容 DeepSeekMoE 的共享专家架构。
应当注意到,也有若干研究指出了 DeepSeekMoE 及其路线中存在的一些问题。
2026 年,Chaudhari 等人在 MoE Lens – An Expert Is All You Need 中通过实验发现,尽管 DeepSeekMoE 在每一层都激活了多个专家进行协同计算,但绝大多数计算结果均由极少数的专业化专家主导。权重最高的单个专家输出已经极其接近整个专家组的联合预测结果。该结果启示了潜在的改进方向:专家裁剪,或进一步降低推理时激活的专家数量,极端情况下甚至仅保留一个。同时,这也印证了 MoE 专家网络的确在概念或领域特征上产生了功能分化。
也是 2026 年的最新研究,Wang 等人在 The Myth of Expert Specialization in MoEs: Why Routing Reflects Geometry, Not Necessarily Domain Expertise 中对传统 MoE 里的「专家专业化」观念提出了根本性的质疑,指出所谓的领域分工有可能只是表征空间几何结构的被动响应。该研究通过理论推导与实证分析指出,router 的激活模式本质上由隐状态的几何相似性决定,而非专家所真正掌握的特定领域的知识。
此外,论文揭示了多个反直觉现象:不同 MoE 模型在处理同一任务时的专家重叠率极低,且 Prefill 阶段的路由无法预测 Rollout 阶段;尤其在推理模型深层,语义完全无关的输入也会因几何结构收敛而激活近乎相同的专家。这表明 MoE 的专家激活极难被人类进行语义解读,其背后凸显了路由机制中几何结构的主导地位,为评估和优化 DeepSeekMoE 路线中的专家分工带来了全新的理论挑战。
参考文献:
- Dai, Damai, Chengqi Deng, Chenggang Zhao, Runxin Xu, Huazuo Gao, Deli Chen, Jiashi Li, Wangding Zeng, Xingkai Yu, Yu Wu, Zhenda Xie, Y. K. Li, Panpan Huang, Fuli Luo, Chong Ruan, Zhifang Sui and Wenfeng Liang. “DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models.” Annual Meeting of the Association for Computational Linguistics (2024).
- Rajbhandari, Samyam, Conglong Li, Zhewei Yao, Minjia Zhang, Reza Yazdani Aminabadi, Ammar Ahmad Awan, Jeff Rasley and Yuxiong He. “DeepSpeed-MoE: Advancing Mixture-of-Experts Inference and Training to Power Next-Generation AI Scale.” ArXiv abs/2201.05596 (2022): n. pag.
- Wang, Zihan, Deli Chen, Damai Dai, Runxin Xu, Zhuoshu Li, Y. Wu and AI DeepSeek. “Let the Expert Stick to His Last: Expert-Specialized Fine-Tuning for Sparse Architectural Large Language Models.” ArXiv abs/2407.01906 (2024): n. pag.
- Olson, Matthew Lyle, Neale Ratzlaff, Musashi Hinck, Man Luo, Sungduk Yu, Chendi Xue and Vasudev Lal. “Probing Semantic Routing in Large Mixture-of-Expert Models.” Conference on Empirical Methods in Natural Language Processing (2025).
- Park, Sumin and Noseong Park. “How Many Experts Are Enough? Towards Optimal Semantic Specialization for Mixture-of-Experts.” AAAI Conference on Artificial Intelligence (2025).
- Hu, Rizhen, Yuan Cao, Boao Kong, Mou Sun and Kun Yuan. “Synergistic Intra- and Cross-Layer Regularization Losses for MoE Expert Specialization.” ArXiv abs/2602.14159 (2026): n. pag.
- Chaudhari, Marmik, Idhant Gulati, Nishkal Hundia, Pranav Karra and Shivam Raval. “MoE Lens – An Expert Is All You Need.” (2026).
- Wang, Xi, Soufiane Hayou and Eric T. Nalisnick. “The Myth of Expert Specialization in MoEs: Why Routing Reflects Geometry, Not Necessarily Domain Expertise.” (2026).
后记
按最初规划的大纲,本文至少应还有下面五个章节:
- 2024. DeepSeek-V2:MLA with MoE
- 2024. DeepSeek-V3:无辅助损失的负载均衡
- 2026. DeepSeek-V4:CSA, HCA, mHC 长上下文工程
- MoE 尚未解决之局限
- 附录:稀疏矩阵理论简述
但写到这里,这篇文章已经足够长了,且基本梳理完了主线——MoE 的基础理论。此外,仅仅是「2024. DeepSeek-V2:MLA with MoE」这一章就需要非常之多的额外篇幅。综合考虑下,我决定让本文在这里结束。
若以后有机会,或许我会在新的文章中以专题的形式单独整理并分析这些内容。