本人没有能力开拓什么,只能综合前辈们的观点尽量感悟;没有打算、更没有能力深入研究收缩估计,不过是对Stein’s paradox的奇怪现象感到诧异,来了兴趣,所以查阅多手资料后写下了本文。
Estimation with Quadratic Loss
ESTIMATION WITH QUADRATIC LOSS - Yale University
1961年Willard James与Charles Stein的文章,在这里James-Stein估计被首次提出,点击此处下载论文。
大规模推断讨论班:经验贝叶斯与 James-Stein 估计量 - GitHub
这篇文章非常系统地从经验Bayes观点引出了Stein理论与Robbins理论,读完后收获颇丰,本文也有所参考。也说明了,所谓“频率学派”、“贝叶斯学派”的对立,“贝叶斯世界观”等描述并不准确,频率方法和Bayes方法不是水火不容的,统计学发展到今天,他们本身的界限就比较模糊。
赵世舜. 矩阵加权估计及James-Stein估计的再研究 [D]. 吉林:吉林大学,2006.
感谢这篇博士论文为我提供的帮助,第二章定理证明的思路是源自于这份文献的;好像在2017年赵已经在吉林大学数学学院升任教授职务了。
~~本文不是正经的论文,懒得划出具体的引用😊~~以上文献本身亦引用了较多文献,如果有兴趣,不妨也读一读。
本文用到了一些缩写:MLE指极大似然估计,UMVUE指一致最小方差无偏估计,MSE指均方误差,G-M定理指高斯-马尔可夫定理。
the James-Stein Estimator
众所周知,$p$元正态分布总体$N_p(\boldsymbol{\mu},\sigma^2\boldsymbol{I}_p)$数学期望的MLE是样本均值,即$\hat{\boldsymbol{\mu}}^{(MLE)}=\bar{\boldsymbol{X}}=\sum\limits^n_{i=1}\frac{\boldsymbol{X}_i}{n}$,是一个十分符合直觉且自然的统计量,由于他的简单直接,通常多数人也会采取他为总体期望的估计。事实上,由于正态分布族系指数族,并且$\bar{\boldsymbol{X}}$是$\boldsymbol{\mu}$是充分完备统计量,故根据Lehmann–Scheffé定理,样本均值是总体期望的UMVUE——这意味着,在无偏估计中样本均值的方差是最小的,可见样本均值是一个性质优良的估计。进一步地,$\mathrm{Var}(\bar{\boldsymbol{X}})$达到了Cramer-Rao下界。
但是,这并不意味着样本均值在任何意义下都是最“好”的!1961年由Willard James和Charles Stein基于1956年Charles Stein提出的早期版本所改进得到的James-Stein estimator(下简称JSE)就是这样一个例子,当用$\mathrm{SE}$表示的样本均值的标准误时,有
$$ \hat{\boldsymbol{\mu}}^{(JSE)}=\left(1-\frac{(p-2)\cdot\mathrm{SE}}{\bar{\boldsymbol{X}}^T\bar{\boldsymbol{X}}}\right)\cdot\bar{\boldsymbol{X}}\tag{1} $$$(1)$式可视为样本量$n=1$的推广,如果只有一个样本,则$(1)$退化为
$$ \hat{\boldsymbol{\mu}}^{(JSE)}_{n=1}=\left(1-\frac{(p-2)\cdot\sigma^2}{\Vert \boldsymbol{X}\Vert^2}\right)\cdot\boldsymbol{X}\tag{2} $$相较于样本均值,JSE的方差显著减小了;尽管失去了无偏性,但渐进无偏,最重要的是在$p\geqslant3$情况下其MSE严格小于样本均值,这时JSE严格一致优于样本均值,这一现象也被称为Stein’s paradox。当p=2时显然JSE等价于样本均值。
这个结论第一眼看起来真的出人意料!这似乎违背经验,毕竟在我们的印象中,寻找、构造UMVUE一直都是统计学家的“毕生追求”,然而JSE的出现却表明,在非无偏估计家族中、在某些情况下,我们或许有比UMVUE更好的选择(这具体取决于我们在特定情境下如何定义“损失”标准)。
这也深刻地说明了,UMVUE其实并没有设想的那般“绝对的好”,当我们把眼光放宽到无偏估计,可能还有更“好”的估计在等着我们发掘。JSE就揭示了,**当维数大于2,样本均值作为UMVUE就未必还是最好的估计!**换句话说,在低维可容许的样本均值,在高维是不可容许的,这侧面印证了低维直觉放在高维中很可能是错误的,高维统计中还有很多这样的例子。
Tip: 由于正态分布的样本均值仍服从正态分布,为简便起见,后文中如若未做特别说明,则只考虑$n=1$的情况,不再区分$\bar{\boldsymbol{X}}$与$\boldsymbol{X}$。
James-Stein型估计的风险
这里将按照赵世舜在其博士学位论文中所给出的,仿照1981年Stein、1990年Brandwein与Strawderman给出的较为简单的证明,证明当$0
看过1961年Willard James与Charles Stein的论文原文,这部分没有看懂,所以不按那最古老的方法证明风险一致地小了。
引理 1 (成平 等,1985) 当$X\sim N(\mu,\sigma^2)$,$h(x)$可微且$\lim\limits_{x\to\infty}\frac{h(x)}{e^{\frac12(x-\mu)^2}}$,有
$$ \mathbb{E}\big[(h(X)(X-\mu)\big]=\mathrm{Cov}\big(X,h(Y)\big)=\sigma^2\mathbb{E}\big[h'(X)\big]\tag{3} $$在后文的证明中只会用到$\sigma^2=1$的情形。
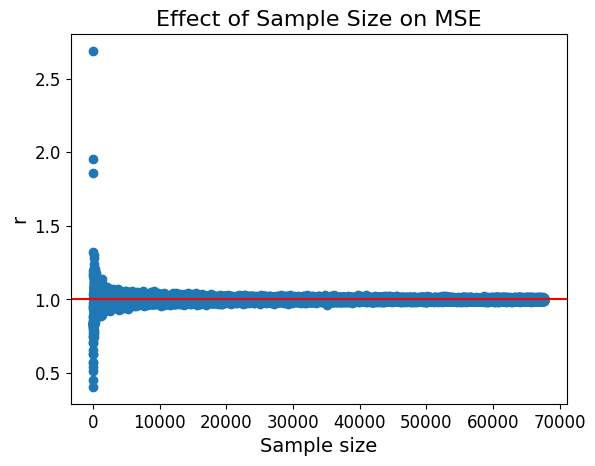
定理 1 以二次损失定义风险,设$\boldsymbol{X}\sim N_p(\boldsymbol{\mu},\sigma^2\boldsymbol{I}_p)$,则当$0 易见当$a=p-2$、$b=0$,$\hat{\delta}_{a,b}=\hat{\boldsymbol{\mu}}^{(JSE)}$,该定理更具有一般性。 证明: 首先容易知道, 观察$\mathbb{E}\left(\frac{\boldsymbol{X}^T(\boldsymbol{X}-\boldsymbol{\mu})}{b+\boldsymbol{X}^T\boldsymbol{X}}\right)$,根据引理 1,有 将$(11)$式代入$(6)$式,则 不过,至今没有很好的办法确定最佳的$a$、$b$。赵世舜在他的博士学位论文中指出,有理由认为选择合适的$b$是比取$b=0$更“好”的,尽管JSE中取$b=0$。 值得说明的是,即使$\sigma^2$是未知的,用$\sigma^2$的估计$\hat{\sigma}^2$代替$\sigma^2$,James-Stein型估计的风险依然一致小于$\boldsymbol{X}$,这就不再赘述了。 通过下述代码直观地可视化JSE与MLE估计效果上的差异, 为保证结果可复现,设置种子 由于$p$元正态分布的样本均值$\bar{\boldsymbol{X}}$也服从$p$元正态分布,而且样本量越大,$\mathrm{tr}(\mathrm{Cov}\bar{\boldsymbol{X}})$越小,所以理论上JSE与MLE都会逐渐贴近总体期望。以 可视化结果如下: 可以看出,当样本量较小的情况下,在MSE准则下JSE是明显优于样本均值的,随着样本量的增大二者差异逐渐减小,均向$0$收敛。不过在前面本文已经证明了,JSE是一致优于样本均值的(而不仅在小样本下)。当样本量较小时,JSE大大优于MLE。 抛开MSE准则不论,从数字的差异上也能直观感受到JSE更加“精准”。对正态总体$N_3\left((0,0,0)^T,\boldsymbol{I}_3\right)$产生的样本量为2的样本进行均值估计,观察估计向量的值: JSE: [ 0.20985719, 0.09654112 ,-1.07700422], the MSE: 0.404433 MLE: [0.27568837, 0.12682561, -1.41485522], the MSE: 0.697968 显然,JSE更接近总体均值$(0,0,0)$。 当总体均值的长度与方差较小时,他们的变化对JSE与MLE间优劣的差异几乎没有影响, 以下为随机抽取的可视化典型样例: 由此可知,在其余条件控制不变的前提下, 伴随$\Vert\boldsymbol{\mu}\Vert^2$的增大,$r$很快收敛于$1$,二者无明显优劣; 伴随$\sigma^2$的增大,$r$趋向于$1$,但在$\sigma^2$较小时JSE优于MLE,随后优势被渐渐削弱。考虑到$\Vert\boldsymbol{\mu}\Vert^2$控制在$10$、样本量$n$控制在$1\sim100$(图中是$n=1$的情况),当$\sigma^2$充分大时讨论估计的优劣没有太大价值,因此可以认为JSE优于MLE; 伴随维数的增大,$r$将收敛到一个明显小于$1$的值,JSE显著优于MLE; 伴随样本量的增大,$r$在$1$附近跌宕起伏且波动幅度不可忽视,估计相对优劣的变化不规律,但是在样本量较小时JSE仍优于MLE,随后优势被渐渐不明显; 无论如何,在绝大多数情况下,JSE的平均风险不超过MLE; 模拟中并未测试但不排除可能的影响因素:变异系数. JSE是一种Shrinkage estimation,中文一般译作收缩估计、压缩估计。收缩估计第一次在Willard James和Charles Stein的《Estimation with Quadratic Loss》中出现,正是在这篇文章中提出了本文的对象JSE,不过“收缩”一词直到1983年Copas在《Regression, Prediction and Shrinkage》中才被提出,在这篇文章中他这样定义了收缩: The fit of a regression predictor to new data is nearly always worse than its fit to the original data. Anticipating this shrinkage leads to Stein‐type predictors which, under certain assumptions, give a uniformly lower prediction mean squared error than least squares. 压缩估计通常会以偏差的较小增长换取显著更小的方差,这被称为方差-偏差权衡策略;换句话说,用均值的偏移换取更小的置信区间。收缩在Bayes推理和惩罚似然推理中是隐式的,在James–Stein型估计的推理中是显式的;JSE可谓是收缩估计的开山之作,同为收缩估计的还有岭估计(ridge estimator)、LASSO估计以及他们的一系列改进,这些都是比较新的方法。 关于收缩估计还有个更简单的例子,通常样本方差通过$\frac{\sum(X_i-\bar{X})^2}{n-1}$给出,将自由度$n-1$作为除数是为了保证估计的无偏性,使用其他的数作为除数会导致估计有偏(一般要保证统计量仍是渐进无偏的),但有可能会得到更小的MSE。至于选取什么数、选取怎样的收缩能减小MSE,一般而言是由总体的峰度决定的,譬如对于正态分布,取$n+1$为除数时会得到最小的MSE,这就是总体方差$\sigma^2$的一个收缩估计。 从正则化的观点看,收缩是一种正则化惩罚的形式,也可以说正则化是实现收缩的手段之一,通过(将参数向$0$或’null’)移动,减轻统计模型的过拟合。将分量向着彼此靠近也是一种收缩,这代表着差异向着$0$移动了——JSE便是将样本均值的每个分量向零收缩,其数量与其与零的距离呈正相合。 尽管JSE如此“年迈”,但在很多情景下仍发挥着不可或缺的重要作用,后续提出的许多新压缩估计也是基于JSE的。不过据李婷婷老师所言,似乎收缩估计这块并没有太多人在研究了。看起来,起码是我校是没有老师在做的。 最初JSE是由Willard James和Charles Stein通过经验Bayes估计(empirical Bayes methods)导出的,正如前文所述,那时还没有诞生shrinkage的概念。在此,我希望通过经验Bayes的解释,让JSE在Bayes框架里看起来更自然。这也说明,选择合适的先验,Bayes估计可以比MLE更“好”——尽管MLE本身也和Bayes框架是兼容的。 与前文类似地,只考虑$n=1$的情况,若$n>1$将$\boldsymbol X$替换为$\bar{\boldsymbol{X}}$即可。假设观测值$\boldsymbol{x}$来自总体期望为$\boldsymbol{\mu}$的正态分布,在$\boldsymbol{\mu}$的条件下$\boldsymbol{x}|\boldsymbol{\mu}\sim f(\boldsymbol{x}|\boldsymbol{\mu})$;而$\boldsymbol{\mu}$本身服从某种分布,记为$\boldsymbol{\mu}\sim g(\boldsymbol{\mu})$,根据Bayes公式,有 其中,先验(prior)是事先给定信息,是试验前已知的信息;似然(likelihood)则是在$\boldsymbol{\mu}$条件下$\boldsymbol{x}$的分布,是观测值,是试验中获取的信息;边际概率$f(\boldsymbol x)=\int g(\boldsymbol\mu)f(\boldsymbol x|\boldsymbol{\mu})\mathrm{d}\boldsymbol\mu$又称边缘概率,可以视作排除了$\boldsymbol\mu$的影响后$\boldsymbol{x}$的分布,即无论$\boldsymbol\mu$取何值$\boldsymbol{x}$的“平均”的分布(想想看,这不就是在求期望么?);后验(posterior)则正是经过试验后对先验的更新与调整,在先验信息下经过试验获得并加入更多的信息后,得到了更准确的估计,这便是后验信息,正是当下所需要的。 既然$\boldsymbol{x}$服从正态分布,$\boldsymbol{x}$的MLE——样本均值也服从正态分布,那么有理由假设$\boldsymbol{\mu}$亦服从正态分布。若令$\boldsymbol{x}|\boldsymbol{\mu}\sim N_p(\boldsymbol\mu,\sigma^2\boldsymbol{I})$,取先验$\boldsymbol{\mu}\sim N_p(\boldsymbol0,\varsigma^2\boldsymbol{I})$,则可以计算后验$\boldsymbol{\mu}|\boldsymbol{x}$的分布, 因此$\boldsymbol{\mu}|\boldsymbol{x}\sim N_p\big(\frac{\varsigma^2}{\varsigma^2+\sigma^2}\boldsymbol{x},\frac{\varsigma^2\sigma^2}{\varsigma^2+\sigma^2}\boldsymbol{I}\big)$,另外可以解出边际概率$f(\boldsymbol x)=\int g(\boldsymbol\mu)f(\boldsymbol x|\boldsymbol{\mu})\mathrm{d}\boldsymbol\mu\sim N_p\big(\boldsymbol0,(\varsigma^2+\sigma^2)\boldsymbol I\big)$。边际概率的积分计算需要一些积分技巧,具体推导可以类比讨论班给出的过程。 根据解出的后验分布,可以得出在先验$\boldsymbol{\mu}\sim N_p(\boldsymbol0,\varsigma^2\boldsymbol{I})$下,总体期望$\boldsymbol\mu$的Bayes估计为 接下来的问题是,$\varsigma^2$也是未知的,所以应当寻找一个对$\varsigma^2$的恰当的估计,于是很自然地想到利用方差的无偏估计代替方差,这一方法在构造多种正态检验统计量中是关键中的关键。 现构造$\frac{\sigma^2}{\varsigma^2+\sigma^2}$的估计,利用前文给出的边际概率$\boldsymbol{X}\sim N_p\big(\boldsymbol0,(\varsigma^2+\sigma^2)\boldsymbol I\big)$,容易知道$\Vert \boldsymbol{X}\Vert^2\sim(\varsigma^2+\sigma^2)\chi^2(p)$,因此$\frac{\sigma^2}{\Vert\boldsymbol{X}\Vert^2}\sim\frac{\sigma^2}{(\varsigma^2+\sigma^2)}\text{inv-}\chi^2(p)$。根据逆$\chi^2$分布的性质,从$\chi^2$分布出发,利用$\Gamma(x)=\displaystyle{\int^\infty_0t^{x-1}e^{-t}\mathrm{d}t}$可以导出: 即: 将$(25^\ast)$式代入$(20)$式,得 $(26)$式和$(2)$式是完全相同的,至此,本文从Bayes估计的角度导出了JSE,提供了JSE的Bayes解释。从这个视角看,常数$p-2$也就没那么突兀了,甚至可以说是由逆$\chi^2$分布均值的性质所决定的。 $^{\ast}$注:$(25^\ast)$式中可以看出$\frac{1}{\Vert\boldsymbol{X}\Vert^2}$是$\frac{1}{(\varsigma^2+\sigma^2)(p-2)}$的无偏估计,但参考Duke大学STA732统计推断讲义第11节Empirical Bayes and Hierarchical Bayes,其实$\frac{1}{\Vert\boldsymbol{X}\Vert^2}$还是$\frac{1}{(\varsigma^2+\sigma^2)(p-2)}$的UMVUE。 最后,上文的推导中运用了自由度为$v$的逆$\chi^2$分布均值为$\frac{1}{v-2}$的结论,在此补充中心化逆$\chi^2$分布的均值与方差的解法,来源StackExchange: 相关文献与扩展阅读: 赵世舜在博士学位论文中完成了这项工作,他证明了可以将JSE推广至矩阵形式,而且保持了良好的性质。 推广的思想与动机是,根据随机变量二次型期望理论,当$\boldsymbol{X}\sim N_p(\boldsymbol{\mu},\sigma^2\boldsymbol{I}_p)$,有$\mathbb{E}(\boldsymbol{X}^T\boldsymbol{X})=\boldsymbol{\mu}^T\boldsymbol{\mu}+p\sigma^2$,因此可以将JSE的估计对象改写 于是联想到将估计的形式推广为如下向量表示: 将未知参数用相应的估计量替代即可得到JSE的矩阵推广形式。 赵世舜证明了JSE的矩阵推广形式拥有至多与JSE相等的的MSE,下展示赵世舜博士学位论文中的这一部分结果: 此外,还有: 该定理的证明参见原文。 如果线性模型的残差被假设服从正态分布,很容易把JSE应用到线性模型回归系数的估计中。推导与证明的过程不再赘述,仿照着上文即可,只给出结果: 其中$p$是回归系数的个数,$\boldsymbol{X}$是设计矩阵;当G-M定理的条件成立且$p>2$时,该估计一致优于OLS。 线性模型的JSE推导与诸多性质的证明本文不再深究了,可以参考: 本文到这里正式结束了。或许后来的我随便翻看着本文,会感慨:原来读本科的时候,我还有毅力去尝试着学习。 本文的写作中参考了许多相关文献,真正的原创大概只有第三章的可视化与第五章的证明,事实上第五章也只是在其他文献基础上做了推广的推导,在原文中只展示了$\sigma^2=1$的情况。可视化JSE与MLE的估计效果
1import numpy as np
2np.random.seed(1)
3
4mean = [0,0,0]
5sigmaSq = 1
6N = 1
7p = len(mean)
8
9df = np.random.multivariate_normal(mean, sigmaSq*np.identity(p), size=N)
10
11class Estimator():
12
13 def JSE(self, X, sigmaSq=1):
14 X_bar = np.average(X, axis=0)
15 XX = np.dot(X_bar, X_bar)
16 sigmaSq_bar = 1 / df.shape[0]
17 theJSE = (1-(df.shape[1]-2)*sigmaSq_bar/XX)*X_bar
18 return theJSE
19
20 def MLE(self, X):
21 return np.mean(df, axis=0)
22
23 # sklearn.metrics.mean_squared_error
24 def MSE(self, X_estimate, X_actual):
25 X_est = np.array(X_estimate)
26 X_act = np.array(X_actual)
27 return np.sum(np.square(X_est-X_act))/X_est.size
28
29 def compare(self, X, X_actual, show=True):
30 estimate_JSE = self.JSE(X)
31 estimate_MLE = self.MLE(X)
32 MSE_JSE = self.MSE(estimate_JSE, X_actual)
33 MSE_MLE = self.MSE(estimate_MLE, X_actual)
34 if show == True:
35 print("JSE: {}, the MSE: {:<8f}".format(estimate_JSE, MSE_JSE))
36 print("MLE: {}, the MSE: {:<8f}".format(estimate_MLE, MSE_MLE))
37 return [estimate_JSE, estimate_MLE, MSE_JSE, MSE_MLE, MSE_MLE/MSE_JSE]
38
39est = Estimator()
40summary = est.compare(df, mean)
np.random.seed(1),部分测试样例如下表:N
$\mu$
$\sigma^2$N=1
$(0,0,0)$
1N=20
$(1,2,\cdots,20)$
1N=10 np.repeat(1,50)
4N=1000
$(1,4,9,16,25)$
1N=5
$(0,0,0,0,0)$
1N=1 np.random.rand(10)
1MSE(JSE) 0.531834 0.030650 0.321131 0.001485 0.000059 0.290441 MSE(MLE) 1.097236 0.030969 0.373426 0.001487 0.122682 1.291636 np.random.rand(10)作为总体均值,观察样本量从1到30时二者的变化。 1import matplotlib.pyplot as plt
2np.random.seed(520)
3
4mean = np.random.rand(10)
5sigmaSq = 1
6N_max = 30
7p = len(mean)
8
9mseJSE_n = np.empty(N_max, float)
10mseMLE_n = np.empty(N_max, float)
11
12for n in range(1, (N_max+1)):
13 df = np.random.multivariate_normal(mean, sigmaSq*np.identity(p), size=n)
14 summary = est.compare(df, mean, show=False)
15 mseJSE_n[n-1] = summary[2]
16 mseMLE_n[n-1] = summary[3]
17
18plt.plot(mseJSE_n, 'o-', label='MSE(JSE)', linewidth=2)
19plt.plot(mseMLE_n, 'o-', label='MSE(MLE)', linewidth=2)
20
21plt.xlabel('Sample size', fontsize=14)
22plt.ylabel('MSE', fontsize=14)
23plt.title('Comparison', fontsize=16)
24plt.legend(fontsize=12)
25
26plt.tick_params(axis='both', which='major', labelsize=12)
27
28# plt.savefig('visual comparison.svg', dpi=1200, format='svg')
29plt.show()

为探究何种因素会使影响JSE与MLE的相对估计效率,记MLE与JSE的MSE比值为$r$,$r$越小表明JSE越优于MLE。在前文代码基础上进行修改,进行模拟试验。下列出典型样例:









Shrinkage Estimation与正则化
JSE的经验Bayes推导与解释

将JSE推广至更佳的矩阵形式


JSE与OLS